En lingüística , la identidad descuidada es una propiedad interpretativa que se encuentra con la elipsis de la frase verbal donde la identidad del pronombre en una VP (frase verbal) elidida no es idéntica a la VP antecedente .
Por ejemplo, el inglés permite que se eliminen los VP, como en el ejemplo (1). El VP elidido se puede interpretar de al menos dos formas, como sigue:
- La lectura "estricta" : la oración (1) se interpreta como (1a), donde el pronombre his denota el mismo referente tanto en el VP antecedente como en el VP elidido. En (1a), el pronombre his se refiere a Juan tanto en la primera como en la segunda cláusula . Esto se hace asignando el mismo índice a John ya ambos pronombres "his". Esto se denomina lectura de “identidad estricta” porque el VP elidido se interpreta como idéntico al VP antecedente.
- La lectura "descuidada" : la oración (1) se interpreta como (1b) donde el pronombre his se refiere a John en la primera cláusula, pero el pronombre his en la segunda cláusula se refiere a Bob. Esto se hace asignando un índice diferente al pronombre his en las dos cláusulas. En la primera cláusula, el pronombre his está co-indexado con John, en la segunda cláusula, el pronombre his está co-indexado con Bob. Esto se denomina lectura de "identidad descuidada" porque el VP elidido no se interpreta como idéntico al VP anterior.
1) John se rascó el brazo y Bob también. una. Lectura estricta : John i se rascó el brazo i y Bob j [se rascó el brazo i ] también. B. Lectura descuidada : John i se rascó el brazo i y Bob j [se rascó el brazo j ] también.
Historia del concepto [ editar ]
La discusión de la “identidad descuidada” entre los lingüistas se remonta a un artículo de John Robert Ross en 1967, [1] en el que Ross identificó la ambigüedad interpretativa en la Frase Verbo elidida de la oración 1) anteriormente mencionada que se encuentra en la introducción. Ross intentó, sin éxito, explicar la identidad "descuidada" utilizando relaciones estructurales estrictamente sintácticas, y llegó a la conclusión de que sus teorías predijeron demasiadas ambigüedades.
Un lingüista llamado Lawrence Bouton (1970) fue el primero en desarrollar una explicación sintáctica de VP-Deletion, [2] comúnmente conocida por los lingüistas contemporáneos como VP - elipsis . La teoría de Bouton de VP-Deletion y la observación de Ross de la identidad descuidada sirvieron como una base importante para que los lingüistas se basaran.
En la próxima década siguieron muchos avances, que proporcionaron gran parte del andamiaje teórico necesario para que los lingüistas aborden los problemas de la “identidad descuidada” hasta el día de hoy. Los más notables de estos avances son la regla de eliminación de VP de Lawrence Bouton (1970), [2] la "regla de VP derivado" de Barbara Partee (1975), [3] y el "enfoque de eliminación" de Ivan Sag (1976), basado en en la regla Derived-VP. Las teorías más allá del descubrimiento inicial de Ross se han extendido más allá de los análisis basados en observaciones de relaciones estructurales, a menudo utilizando formas lógicas y fonéticas.para dar cuenta de casos de identidad estricta y descuidada. El enfoque de eliminación (VP derivado), en combinación con el uso de componentes de forma lógica (LF) y forma fonética (PF) en la sintaxis , es uno de los análisis sintácticos de identidad descuidada más utilizados hasta la fecha.
Analiza [ editar ]
Modelo Y [ editar ]
Este modelo representa el nivel de interfaz del sistema fonológico y el sistema interpretativo que nos dan juicios de forma y significado de la estructura-D . Los primeros teóricos parecían sugerir que la forma fonética y la forma lógica son dos enfoques distintos para explicar la derivación de la elipsis VP.
El análisis de deleción en PF (forma fonética) [ editar ]
Académicos como Noam Chomsky (1955), [4] Ross (1969) [5] y Sag (1976) [1] han sugerido que el proceso responsable de la elipsis de VP es una regla de eliminación sintáctica aplicada al nivel de PF, este proceso se denomina como VP Deletion.
La hipótesis de la deleción de PF asume que el VP elidido está representado sintácticamente pero eliminado en el componente fonológico entre SPELLOUT y PF. Sugiere que la eliminación de VP es el proceso que genera identidades descuidadas porque la co-indexación debe ocurrir con respecto a las condiciones vinculantes .
Ejemplo
2.i) John se comerá su manzana y Sam [VPØ] también. 2.ii) [John i comeré su i manzana] y [Sam j comerá su j manzana].
En el ejemplo 2.i), la eliminación de VP es la razón por la que se deriva un VP nulo. Antes de la eliminación, como se ve en el ejemplo 2.ii), la oración de hecho se leería como "John se comerá su manzana y Sam también se comerá su manzana". Las cláusulas [John comerá su manzana] y [Sam comerá su manzana] comparten un VP idéntico en el sentido de que tienen la misma estructura constituyente , por lo que la segunda cláusula puede eliminarse porque es idéntica a su VP anterior.
Volviendo ahora a la coindexación, esta oración contiene dos constituyentes combinados por la conjunción “y”. Las cláusulas son cada una de las estructuras de oraciones completas independientes, por lo que presumiblemente cada pronombre co-indexaría a su referente en su constituyente para cumplir con las teorías vinculantes. Con esta co-indexación, ilustrada en el ejemplo 2. ii), se produce una lectura descuidada.
Sin embargo, al considerar casos sensibles a las teorías vinculantes, la lectura estricta esperada de la oración 3) violaría el Principio vinculante A. De acuerdo con este principio, una anáfora debe estar vinculada en su dominio vinculante, lo que significa que debe estar vinculada dentro de la misma cláusula que su referente.
3) John se culpó a sí mismo y Bill se culpó a sí mismo
Lectura estricta esperada:
3.i) John i [VP se culpó a sí mismo i ], y Bill j [VP se culpó a sí mismo i ]
Lectura descuidada esperada:
3.ii) John i [VP se culpó a sí mismo i ], y Bill j [VP se culpó a sí mismo j ]
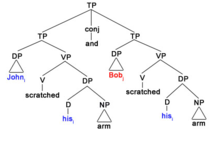
Teniendo esto en cuenta, se observa que las lecturas estrictas son difíciles de obtener en oraciones como esta, porque si el mismo anáfora en el VP elidido está co-indexado con 'John' violaría la Teoría Binding A porque están en cláusulas separadas. . Las relaciones de comando C se representan mediante codificación de colores en el árbol de sintaxis. Como se muestra en el diagrama de árbol e ilustrado en verde, 'John i ' c-se ordena a 'sí mismo i ' en el primer VP. 'Bill j ' por otro lado c-manda 'él mismo j ' en el segundo VP, codificado en color naranja. Debido a los dominios de enlace, los DPLos más cercanos a los anáforas tienen que ser aquellos a los que se unen y co-indexan. Por lo tanto, 'Juan i ' no puede no comandar al 'él mismo j ' en el segundo VP, como se muestra a través de la diferencia en la codificación de colores. En consecuencia, la Teoría de la vinculación A se violaría si la co-indexación del ejemplo 2.i) genera una lectura estricta. Por lo tanto, la hipótesis de eliminación de PF genera lecturas descuidadas porque trata el VP elidido como estructuras idénticas al VP antecedente y la co-indexación está limitada por la localidad.
El análisis de copia en LF (forma lógica) [ editar ]
Según Carnie, [6] el problema de la identidad descuidada puede explicarse utilizando una hipótesis de copia LF. Esta hipótesis afirma que antes de SPELLOUT, el VP elidido no tiene estructura y existe como un VP vacío o nulo (a diferencia de la hipótesis de eliminación de PF, que afirma que el VP elidido tiene estructura a lo largo de la derivación). Solo copiando la estructura del antecedente VP tiene estructura en LF. Estos procesos de copia se producen de forma encubierta de SPELLOUT a LF.
Según LF-copying, la ambigüedad encontrada en la identidad descuidada se debe a diferentes ordenamientos de las reglas de copia para pronombres y verbos. Considere las siguientes derivaciones de la lectura descuidada y la lectura estricta para la oración (4), usando la regla de copia de VP encubierta y la regla de copia de anáfora:
4) Calvin se golpeará a sí mismo y Otto también lo hará.
Lectura descuidada
En la lectura descuidada, la regla de copia de VP se aplica primero, como se puede ver en la oración 5). La regla de copia de VP copia el VP en el antecedente en el VP vacío:
Regla de copia encubierta de VP
5) Calvin [se golpeará a sí mismo] y Otto [se golpeará a sí mismo] también.
Siguiendo la regla de copia de VP, se aplica la regla de copia de anáforas, como se puede ver en la oración 6). La regla de copia de anáforas , que está vinculada a una cláusula, copia los NP en anáforas dentro de la misma cláusula:
Regla encubierta de copia de anáforas
6) Calvin [golpeará a Calvin] y Otto [golpeará a Otto] también.
Lectura estricta
En la lectura estricta, la aplicación de estas reglas ocurre en el orden opuesto. Por lo tanto, primero se aplica la regla de copia de anáforas. Debido al hecho de que el VP vacío no contiene una anáfora, el NP “Otto” no se puede copiar en él. Este proceso se puede ver en la oración 7):
Regla encubierta de copia de anáforas
7) Calvin [golpeará a Calvin] y Otto [vp Ø] también.
Siguiendo la regla de copia de anáforas, se aplica la regla de copia de VP y produce la oración en 8):
Regla de copia encubierta de VP
8) Calvin [golpeará a Calvin] y Otto [golpeará a Calvin] también.
La derivación utilizada en esta hipótesis de copia LF se puede encontrar aquí .
Combinación de PF y LF [ editar ]
Basándose en el trabajo de Bouton (1970) y Ross (1969), Barbara Partee (1975) [3] desarrolló lo que ha llegado a ser uno de los enfoques más importantes e influyentes para explicar la VP hasta la fecha, la Regla VP Derivada , que introduce un operador nulo a nivel de vicepresidente. Poco después, Ivan A. Sag (1976) [1] desarrolló el enfoque VP derivado por deleción y Edwin S. Williams (1977) [5] desarrolló el enfoque VP derivado interpretativo . Muchas personas todavía utilizan estas reglas en la actualidad.
Regla VP derivada: [3]
Según Williams [5] (1977), la regla VP derivada convierte VP en la estructura de la superficie en propiedades escritas en notación lambda. Esta es una regla muy importante que se ha construido a lo largo de los años para dar sentido a la identidad descuidada. Muchos lingüistas utilizan esta regla VP como base para sus reglas de puntos suspensivos.
Enfoque de VP derivado de la eliminación: [1] [ editar ]
Ivan Sag propuso dos formas lógicas, una de las cuales el pronombre correferencial se reemplaza por una variable ligada . [1] Esto conduce a la regla de interpretación semántica que toma pronombres y los convierte en variables ligadas. [1] Esta regla se abrevia como Pro → BV, donde “Pro” significa pronombre y “BV” significa variable ligada.
Ejemplo de oración simple
9) [Betsy i ama a su i perro]
La lectura estricta de la oración 9) es que "Betsy ama a su propio perro". La aplicación de Pro → BV luego deriva la oración en 9.i):
9 i) [Betsy i ama a su j (o) de perro x]
Donde su j es otra persona o la x es el perro de otra persona
Ejemplo complejo
10) Betsy i ama a su i perro y arena j hace demasiado ∅
donde ∅ = ama a su perro
Lectura estricta
La lectura estricta de 10) es "Betsy ama al perro de Betsy y Sandy también ama al perro de Betsy", lo que implica que ∅ es un vicepresidente que ha sido eliminado. Esto se representa en la siguiente oración:
10.i) Betsy i λx (x ama a su i perro) y Sandy λy (y ama a su i perro)
Los VP que están representados por λx y λy son sintácticamente idénticos. Por esta razón, el que está siendo c-comandado (λy) se puede eliminar.
Esto entonces forma:
10.ii) Betsy me encanta su i perro y Sandy j también ∅
Lectura descuidada
La lectura descuidada de esta oración es "Betsy ama al perro de Betsy y Sandy ama al perro de Sandy". Es decir, ambas mujeres aman a su propio perro. Esto se representa en la siguiente oración:
10.iii) Betsy i λx (x ama a su i perro) y Sandy j λy (y ama a su j perro)
Dado que las cláusulas integradas son idénticas, la lógica de esta forma es que la variable x debe estar vinculada al mismo sintagma nominal en ambos casos. Por lo tanto, "Betsy" está en la posición dominante que determina la interpretación de la segunda cláusula.
La regla Pro → BV que convierte pronombres en variables ligadas se puede aplicar a todos los pronombres.
Esto permite que la oración en 10.iii) sea:
10.iv) Betsy i λx (x ama al perro de x) y Sandy j λy (y ama al perro de y)
Otra forma en que el VP puede ser sintácticamente idéntico es, si λx (A) y λy (B) donde cada instancia de x en A tiene una instancia correspondiente de y en B. Entonces, como en el ejemplo anterior, para todas las instancias de x hay es una instancia correspondiente de y y, por lo tanto, son idénticas y el VP al que se le ordena c puede eliminarse.
Derivación paso a paso [ editar ]
En el enfoque de Sag, VP Ellipsis se analiza como una deleción que tiene lugar entre la estructura S (estructura superficial) y PF (estructura superficial). Se afirma que el VP eliminado es recuperable al nivel de LF debido a la variación alfabética que se mantiene entre dos expresiones λ. [7] En este enfoque de eliminación, la identidad descuidada es posible, primero, mediante la indexación de anáforas, y luego mediante la aplicación de una regla de reescritura de variables.
La siguiente es una derivación paso a paso, tomando en consideración las formas fonéticas y lógicas, lo que explica una lectura descuidada de la oración "John se culpó a sí mismo y Bill también".
Mapeo LF
Estructura profunda a estructura superficial:
11) John i [ vicepresidente se culpó a sí mismo], y Bill j [ vicepresidente se culpó a sí mismo] también. [7]
En esta oración, los vicepresidentes [se culpó a sí mismo] están presentes, pero aún no hacen referencia a ningún tema. En la oración 12), se aplica la Regla de VP Derivado, reescribiendo estos VP usando la notación lambda.
Regla de VP derivada
12) John i [ VP λx ( x se culpa a sí mismo)], Bill j [ VP λy ( y se culpa a sí mismo)], también. [7]
La regla VP derivada ha derivado dos VP que contienen operadores λ separados con variables referenciales vinculadas en cada cláusula antecedente. La siguiente regla, Indexación, co-indexa anáforas y pronombres a sus sujetos.
Indexación
13) John i [ VP λx (x culpo a él i )], Bill j [ VP λy (y culpo a él j )], también. [7]
Como vemos, las anáforas han sido co-indexadas a sus respectivos NP. Por último, la regla de reescritura de variables reemplaza pronombres y anáforas con variables en forma lógica.
Pro -> BV
Forma lógica:
14) John i [ VP λx (x culpar x)], Bill j [ VP λy (y culpar y)], también. [7]
Mapeo de PF
Estructura profunda a estructura superficial:
15) John [ VP se culpó a sí mismo], y Bill [ VP se culpó a sí mismo] también. [7]
Aquí vemos que tanto John como Bill preceden al mismo vicepresidente, [culparse a sí mismo]. Es importante señalar que cualquier significado, en este caso al que hace referencia el Sujeto la Anáfora “él mismo”, se determina en LF y, por lo tanto, se deja fuera de la forma fonética.
Eliminación de vicepresidente
16) John [ VP se culpó a sí mismo], y Bill ____ también. [7]
Se produce la eliminación de VP, que en efecto elimina al VP [culparse a sí mismo] de la segunda cláusula Bill [culparse a sí mismo]. Nuevamente, es importante tener en cuenta que esta eliminación ocurre estrictamente en el nivel fonético y, por lo tanto, [culparse a sí mismo] todavía existe en el componente LF, a pesar de que se eliminó en PF.
Do-apoyo
Forma fonética:
17) John [ VP se culpó a sí mismo], y Bill también hizo ____. [7]
Por último, se implementa Do-Support, llenando el espacio vacío creado por VP Deletion con did . Este es el último paso que ocurre en PF, dejando que la oración se realice fonéticamente como "John se culpó a sí mismo y Bill también". Debido a las reglas promulgadas en el componente LF de la derivación, aunque did ha reemplazado fonéticamente al VP [culparse a sí mismo], su significado es el mismo que el establecido en LF. Por lo tanto, "Bill también lo hizo" puede interpretarse descuidadamente como "Bill se culpó a sí mismo", como en "Bill culpó a Bill".
Enfoque de VP derivado de la interpretación [ editar ]
En su aproximación al problema de la identidad descuidada, Williams (1977) también adopta la Regla Derived VP. [8] También sugiere que los anáforas y los pronombres se reescriban como variables en LF mediante una regla de reescritura de variables. Posteriormente, mediante el uso de la regla VP, estas variables se copian en el VP elidido. Siguiendo este enfoque, son posibles tanto las lecturas descuidadas como las estrictas. Los siguientes ejemplos pasarán por la derivación de la oración 18.i) como una lectura descuidada:
Lectura descuidada
18.i) John visita a sus hijos el domingo y Bill también lo hace [ VP ∅]. [8]
Como se puede ver en esta oración, el VP no contiene estructura. En la oración 19.i), se aplica la regla de VP derivado, que reescribe el VP usando la notación lambda:
Regla de VP derivada
19.i) John [ VP λx (x visita a sus hijos)] y Bill también lo hace [ VP ∅]. [8]
A continuación, la regla de reescritura de variables transforma pronombres y anáforas en variables en LF:
Regla de reescritura variable
20.i) John [ VP λx (x visita a los hijos de x)] y Bill también lo hace [ VP ∅]. [8]
La regla de VP luego copia la estructura de VP en el VP elidido:
Regla VP
21.i) John [ VP λx (x visita a los hijos de x)] y Bill también [ VP λx (x visita a los hijos de x)]. [8]
La principal diferencia entre la lectura descuidada y la estricta radica en la regla de reescritura variable. La presencia de esta regla permite una lectura descuidada porque las variables están vinculadas por el operador lambda dentro del mismo VP. Al convertir el pronombre his en 20.i) en una variable, y una vez que el VP se copia en el VP elidido en la oración 21.i), Bill puede vincular la variable en el VP elidido. Por lo tanto, para obtener la lectura estricta, este paso simplemente se omite.
Lectura estricta
18.ii) John visita a sus hijos los domingos y Bill también lo hace [ VP ∅].
El VP se reescribe usando notación lambda:
Regla de VP derivada
19.ii) John [ VP λx (x visita a sus hijos)] y Bill también lo hace [ VP ∅].
La estructura de VP se copia en el VP elidido:
Regla VP
21.ii) John [ VP λx (x visita a sus hijos)] y Bill también [ VP λx (x visita a sus hijos)].
Debido al hecho de que el pronombre his ya está co-indexado con John, y no se reescribió como una variable antes de ser copiado en el VP elidido, no hay forma de que esté vinculado por Bill. Por lo tanto, la lectura estricta se obtiene omitiendo la regla de reescritura de variables.
Teoría del cambio de centrado [ editar ]
La idea de "centrar", también conocida como "enfocar", ha sido discutida por numerosos lingüistas, como A. Joshi, S. Weinstein y B. Grosz. [9] Esta teoría se basa en el supuesto de que en la conversación ambos participantes comparten un enfoque psicológico hacia una entidad que es central en su discurso. Hardt (2003), [10] utilizando este enfoque teórico central, sugiere que en el discurso, un cambio de enfoque de una entidad a otra hace posible que ocurran lecturas descuidadas.
En los dos ejemplos siguientes, el superíndice * representa el foco actual del discurso, mientras que el subíndice * significa una entidad que está en referencia al foco del discurso. Considere los siguientes dos ejemplos:
Lectura estricta
22) John * se rascó * el * brazo y Bob se rascó * el * brazo
En el ejemplo anterior, no hay un cambio desde el enfoque inicial, por lo que surge el significado estricto, donde tanto John como Bob rascaron el brazo de John, ya que John es donde se establece el enfoque y permanece durante todo el discurso. Por el contrario, un cambio de enfoque fuera del enfoque del discurso inicial, como en el ejemplo siguiente, da lugar a una lectura descuidada.
Lectura descuidada
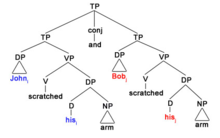
23) John * se rascó * el * brazo y Bob * se rascó * el * brazo
Ahora surge la lectura descuidada de la oración, donde John se rascó el brazo (el brazo de John) y Bob se rascó el brazo (el brazo de Bob). El cambio de enfoque ha incluido a Bob como el sustantivo principal y esto permite que el pronombre his se refiera a su superíndice * más cercano, en este caso, Bob.
Cabe señalar que esta es una explicación simplificada de la teoría del centrado. Este enfoque se puede explorar más a fondo en el artículo de Hardt de 2003 [10] . Aunque más allá del alcance de esta discusión, el uso de Hardt de la Teoría del Centrado también puede explicar el acertijo de dos elipsis de pronombres y el acertijo de dos actitudes de pronombres, dos acertijos que antes de la Teoría de Centrado no podían explicarse adecuadamente.
Implicaciones translingüísticas de una identidad descuidada [ editar ]
Se han observado casos de identidad descuidada en varios idiomas, sin embargo, la mayoría de las investigaciones se han centrado en casos de identidad descuidada que ocurren en inglés. Desde un punto de vista interlingüístico, la identidad descuidada se analiza como un problema universal, que se encuentra en la estructura sintáctica subyacente básica que comparten todas las lenguas. Para obtener ejemplos y análisis de identidad descuidada en otros idiomas, como japonés , [11] coreano , [12] y chino , [13] consulte los siguientes artículos en la sección de referencias a continuación. También sigue una explicación en profundidad de la identidad descuidada en mandarín.
Identidad descuidada en mandarín [ editar ]
Shì-support (是) [ editar ]
En el marco generativo, se ha argumentado que la contraparte abierta de do -support en inglés es el shì -support en mandarín moderno. Similar al do -support, shì -support puede permitir construcciones que no están completamente desarrolladas.
Ejemplo
1. Zhangsan xihuan ta-de didi. Lisi ye shi. Zhangsan, como su hermano menor, Lisi, también 'A Zhangsan le gusta su hermano menor; Lisi también lo hace '
Lectura estricta esperada:
1. i) A Zhangsan le gusta su hermano menor, ya Lisi también le gusta el hermano menor de Zhangsan.
Lectura descuidada esperada:
1. ii) A Zhangsan le gusta su hermano menor ya Lisi le gusta su propio hermano menor.
Como indica (1), tanto las lecturas estrictas como las descuidadas están igualmente disponibles, similar al caso en inglés.
Aunque shì -support puede sustituir a los verbos estatales en mandarín moderno, como "xihuan" (como), no es compatible con todos los tipos de verbos. Por ejemplo, los verbos de actividad por sí solos no siempre son compatibles con shì -support.
Ejemplo
2. Zhangsan piping-le ta-de didi. ? / ?? Lisi ye shi. Zhangsan criticar-Asp. su hermano menor Lisi también será 'Zhangsan criticó a su hermano menor; Lisi también lo hizo.
Lectura estricta esperada:
2.i) Zhangsan criticó a su propio hermano menor. ? Lisi también criticó al hermano menor de Zhangsan.
Lectura descuidada esperada:
2.ii) Zhangsan criticó a su propio hermano menor. ?? Lisi criticó a su propio hermano menor.
Como indica (2), tanto las lecturas estrictas como las descuidadas están igualmente disponibles, sin embargo, el juicio de las oraciones anteriores puede variar entre hablantes nativos de mandarín moderno.
Para mejorar la aceptabilidad general de la lectura estricta y descuidada de (2), Ai (2014) agregó adverbios a la cláusula de antecedente.
Ejemplo:
3. Zhangsan henhen-de piping-le ta-de didi. Lisi ye shi. Zhangsan enérgicamente-DE critica-Asp. su hermano menor Lisi también será 'Zhangsan criticó enérgicamente a su hermano menor; Lisi también lo hizo.
Lectura estricta esperada:
3.i) Zhangshan criticó enérgicamente a su hermano menor. ?? Lisi también criticó enérgicamente al hermano de Zhangshan.
Lectura descuidada esperada:
3.ii) Zhangsan criticó enérgicamente a su hermano menor. ? Lisi criticó enérgicamente a su propio hermano menor.
Como indica (3), tanto las lecturas estrictas como las descuidadas están igualmente disponibles; sin embargo, según la encuesta mencionada anteriormente, los hablantes nativos de mandarín moderno todavía prefieren la lectura descuidada a la estricta. Es cuestionable analizar (3) basado en la adición de adverbiales según el diagnóstico de distribución equitativa tanto en la lectura estricta como en la descuidada.
Negación en shi-support [ editar ]
La negación en shi-support y la negación en inglés do-support no funcionan de manera idéntica. Cuando está precedido por bu (not) negativo , shi-support no es gramatical, independientemente de si el antecedente lingüístico es afirmativo o negativo.
Ejemplo: [14]
4. * Ta xihuan Zhangsan. Wo bu-shi a él le gusta Zhangsan yo no seré "A él le gusta Zhangsan. A mí no".
5. * Ta bu-xihuan Zhangsan. Wo ye bu-shi él no-como Zhangsan yo tampoco-seré "No le gusta Zhangsan. A mí tampoco".
Sin embargo, si el antecedente lingüístico es negativo, el shi-support puede proporcionar una lectura negativa, aunque el shi-support no esté precedido por el bu (not) negativo .
Ejemplo:
6. Ta bu-xihuan Zhangsan. Wo ye shi. él no-como Zhangsan yo también seré "A él no le gusta Zhangsan. A mí tampoco".
Preguntas en shi-support [ editar ]
Además, las preguntas en shi-support y en inglés do-support no funcionan de manera idéntica.Shi no puede autorizar puntos suspensivos cuando el antecedente lingüístico ocurre en una pregunta.
Ejemplo:
7. A: ¿Shei xihuan Zhangsan? a quien le gusta Zhangsan "¿A quién le gusta Zhangsan?" B: * Wo shi Yo ser "Hago."
Escurrimiento de mandarina [ editar ]
Las tres propiedades esenciales de la identidad descuidada en el lenguaje mandarín incluyen: (1) c-dominante (2) identidad léxica entre palabras-wh y (3) na 'ese' efecto.
C-al mando [ editar ]
Ross (1967) propuso que para que una expresión elidida tenga una identidad descuidada, un pronombre relacionado con la lectura debe estar comandado por su antecedente, como se demuestra en (8a). De lo contrario, la identidad descuidada no está disponible, como en (8b). La purificación del mandarín sigue esta restricción en (9).
Ejemplo [15]
8a. John i sabe por qué me regañó, y María sabe por qué, también.
Lectura estricta esperada:
8a. i) John i sabe por qué me regañó, y Mary J sabe por qué i fue regañado.
Lectura descuidada esperada:
8a. ii) John i sabe por qué me regañó, y Mary J sabe por qué ella j fue regañado.
Ejemplo
8b. La madre de John sabe por qué lo regañaron, y la madre de Mary también sabe por qué.
Lectura estricta esperada:
8b. i) " La madre de John i sabe por qué me regañaron, y la madre de Mary sabe por qué me regañaron".
Lectura descuidada esperada:
8b. ii) * 'La madre de John sabe por qué lo regañaron, y la madre de Mary sabe por qué la regañaron'.
Ejemplo
9a. Zhangsan i bu zhidao [ta i weishenme bei ma], dan Lisi j zhidao (shi) weishenme Zhangsan no sabe por qué PASS regañar pero Lisi sabe por qué "Zhangsan no sabía por qué lo regañaban, pero Lisi sabe por qué".
Lectura estricta esperada:
9a. i) Zhangsan no sabía por qué lo regañaban, pero Lisi sabe por qué regañaban a Zhangsan.
Lectura descuidada esperada:
9a. ii) Zhangsan i no sabía por qué me fue regañado, pero Lisi j sabe por qué j fue regañado.
Ejemplo
9b. [Zhangsan-de muqin] zhidao ta weishenme bei ma, dan [Lisi-de muqin] bu zhidao (shi) weishenme. La madre de Zhangsan-POSS sabe por qué PASS regaña pero la madre de Lisi-POSS no sabe por qué "La madre de Zhangsan sabe por qué lo regañaron, pero la madre de Lisi no sabe por qué"
Lectura estricta esperada:
9b. i) La madre de Zhangsan sabe por qué lo regañaron, pero la madre de Lisi no sabe por qué lo regañaron.
Lectura descuidada esperada:
9b. ii) * La madre de Zhangsan sabe por qué lo regañaron, pero la madre de Lisi no sabe por qué lo regañaron.
Entrada léxica entre palabras-wh [ editar ]
Para derivar una identidad descuidada, se requiere una identidad "léxica" entre el correlato-wh abierto y el remanente-wh, independientemente de la distinción argumento-adjunto. Este es también el caso del sluicing en mandarín, para la identidad del adjunto wh en (9a) y la identidad del argumento wh en (10).
Ejemplo [15]
10. Zhangsan zhidao [shei zai piping tai], dan Lisi bu zhidao shi shei. Zhangsan sabe quien lo critica PROG pero Lisi no sabe ser quien "Zhangsan sabe quién lo está criticando, pero Lisi no sabe quién".
Lectura estricta esperada:
10. i) Zhangsan sabe quién lo está criticando, pero Lisi no sabe quién está criticando a Zhangsan.
Lectura descuidada esperada:
10. ii) Zhangsan sabe quién lo está criticando, pero Lisi no sabe quién se está criticando a sí mismo.
Dadas estas restricciones de identidad léxica, la derivación de la lectura de identidad descuidada predice que se requiere que el antecedente de wh esté abiertamente presente, de lo contrario solo se permite la lectura estricta.
Referencias [ editar ]
- ↑ a b c d e f Sag, IA (1976). "Supresión y forma lógica". Tesis de Doctorado, Instituto Tecnológico de Massachusetts . Nueva York: Garland Publishing.
- ↑ a b Bouton, L (1970). "Formularios profesionales con antecedentes". Artículos de la Sexta Reunión Regional de la Sociedad Lingüística de Chicago . Chicago, IL.
- ↑ a b c Partee, B (1975). "Gramática de Montague y gramática transformacional". Investigación lingüística . 6 (2): 203–300.
- ^ Chomsky, N. (1955) La estructura lógica de la teoría lingüística. Manuscrito, Universidad de Harvard.
- ↑ a b c Williams, ES (1977). "Discurso y forma lógica". Investigación lingüística . 8 (1): 101-139.
- ^ Carnie, Andrew (2013). Sintaxis: una introducción generativa . Chichester, West Sussex: John Wiley & Sons Ltd.
- ↑ a b c d e f g h Kitagawa, Yoshihisa (agosto de 1991). "Copia de identidad". Lenguaje natural y teoría lingüística . 9 (3): 497–536. doi : 10.1007 / bf00135356 . S2CID 189902334 .
- ↑ a b c d e Lobeck, A (1995). Puntos suspensivos: jefes funcionales, licencias e identificación . Nueva York: Oxford University Press.
- ^ Grosz, Barbara; Joshi, A .; Weinstein, S. (1995). "Centrar: un marco para modelar la coherencia local del discurso". Lingüística computacional . 21 (2).
- ↑ a b Hardt, D. (2003). "Identidad descuidada, encuadernación y centrado". Actas de la teoría de la semántica y la lingüística : 109-126. ProQuest 85633705 .
- ^ Hoji, H (1998). "Objeto nulo e identidad descuidada en japonés". Investigación lingüística . 29 (1): 127-152. doi : 10.1162 / 002438998553680 . S2CID 57560087 .
- ^ Kim, S (1999). "Identidad descuidada / estricta, objetos vacíos y puntos suspensivos NP". Revista de Lingüística de Asia Oriental . 8 (4): 255–284. doi : 10.1023 / a: 1008354600813 . S2CID 118578452 .
- ^ Lujuria, B; F. Guo; C. Foley; Y. Chien; C. Chiang (1996). "Enlace de variable de operador en el estado inicial: un estudio translingüístico de estructuras de elipsis VP en chino e inglés". Cahiers de Linguistique Asie Orientale . 25 (1): 3–34. doi : 10.3406 / clao.1996.1490 .
- ^ Soh, Hooi Ling (2007). "Puntos suspensivos, último recurso y el shi auxiliar ficticio 'Be' en chino mandarín". Investigación lingüística. 180-181
- ↑ a b Wei, Ting-Chi (2009). "Algunas notas sobre la identidad descuidada en Mandarin Sluicing". Concéntrico: Estudios de Lingüística. 272