(Para obtener una lista de la notación lógica matemática utilizada en este artículo, consulte Notación en probabilidad y estadística y / o Lista de símbolos lógicos ).
Una red bayesiana (también conocida como red Bayes , red Bayes , red de creencias o red de decisiones ) es un modelo gráfico probabilístico que representa un conjunto de variables y sus dependencias condicionales mediante un gráfico acíclico dirigido (DAG). Las redes bayesianas son ideales para tomar un evento que ocurrió y predecir la probabilidad de que cualquiera de las posibles causas conocidas fuera el factor contribuyente. Por ejemplo, una red bayesiana podría representar las relaciones probabilísticas entre enfermedades y síntomas. Dados los síntomas, la red se puede utilizar para calcular las probabilidades de presencia de diversas enfermedades.
Los algoritmos eficientes pueden realizar inferencias y aprendizaje en redes bayesianas. Las redes bayesianas que modelan secuencias de variables ( por ejemplo , señales de voz o secuencias de proteínas ) se denominan redes bayesianas dinámicas . Las generalizaciones de redes bayesianas que pueden representar y resolver problemas de decisión bajo incertidumbre se denominan diagramas de influencia .
Modelo gráfico
Formalmente, las redes bayesianas son grafos acíclicos dirigidos (DAG) cuyos nodos representan variables en el sentido bayesiano : pueden ser cantidades observables, variables latentes , parámetros desconocidos o hipótesis. Los bordes representan dependencias condicionales; los nodos que no están conectados (ninguna ruta conecta un nodo con otro) representan variables que son condicionalmente independientes entre sí. Cada nodo está asociado con una función de probabilidad que toma, como entrada, un conjunto particular de valores para las variables principales del nodo y da (como salida) la probabilidad (o distribución de probabilidad, si corresponde) de la variable representada por el nodo. Por ejemplo, si los nodos padres representan Variables booleanas , entonces la función de probabilidad podría representarse mediante una tabla de entradas, una entrada para cada uno de los posibles combinaciones de padres. Se pueden aplicar ideas similares a gráficos no dirigidos, y posiblemente cíclicos, como las redes de Markov .


Ejemplo
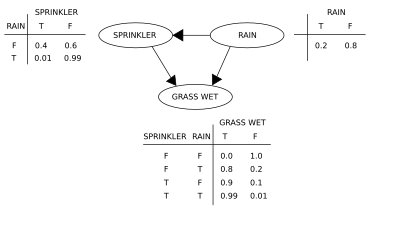
Dos eventos pueden hacer que el césped se moje: un aspersor activo o lluvia. La lluvia tiene un efecto directo sobre el uso del aspersor (es decir, que cuando llueve, el aspersor generalmente no está activo). Esta situación se puede modelar con una red bayesiana (que se muestra a la derecha). Cada variable tiene dos valores posibles, T (verdadero) y F (falso).
La función de probabilidad conjunta es, por la regla de probabilidad de la cadena ,

donde G = "Hierba mojada (verdadero / falso)", S = "Aspersor encendido (verdadero / falso)" y R = "Lloviendo (verdadero / falso)".
El modelo puede responder preguntas sobre la presencia de una causa dada la presencia de un efecto (la llamada probabilidad inversa) como "¿Cuál es la probabilidad de que llueva, dado que el césped está húmedo?" utilizando la fórmula de probabilidad condicional y sumando todas las variables molestas :

Usando la expansión para la función de probabilidad conjunta y las probabilidades condicionales de las tablas de probabilidad condicional (CPT) indicadas en el diagrama, se puede evaluar cada término en las sumas del numerador y denominador. Por ejemplo,


Luego, los resultados numéricos (subindicados por los valores de las variables asociadas) son

Para responder una pregunta intervencionista, como "¿Cuál es la probabilidad de que llueva, dado que mojamos el césped?" La respuesta se rige por la función de distribución conjunta posterior a la intervención.

obtenido eliminando el factor de la distribución previa a la intervención. El operador do obliga a que el valor de G sea verdadero. La probabilidad de lluvia no se ve afectada por la acción:


Para predecir el impacto de encender el rociador:

con el término eliminado, mostrando que la acción afecta a la hierba pero no a la lluvia.

Estas predicciones pueden no ser factibles dadas las variables no observadas, como en la mayoría de los problemas de evaluación de políticas. El efecto de la acciónSin embargo, todavía se puede predecir siempre que se satisfaga el criterio de la puerta trasera. [1] [2] Establece que, si se puede observar un conjunto Z de nodos que d -separa [3] (o bloquea) todas las rutas de puertas traseras de X a Y, entonces


Una ruta de acceso de la puerta trasera es uno que termina con una flecha en X . Los conjuntos que satisfacen el criterio de la puerta trasera se denominan "suficientes" o "admisibles". Por ejemplo, el conjunto Z = R es admisible para predecir el efecto de S = T en G , porque R d desconectadores la trayectoria (solamente) de la puerta trasera S ← R → G . Sin embargo, si no se observa S , ningún otro conjunto d separa este camino y el efecto de encender el aspersor ( S = T ) sobre el césped ( G) no se puede predecir a partir de observaciones pasivas. En ese caso, P ( G | do ( S = T )) no está "identificado". Esto refleja el hecho de que, a falta de datos intervencionistas, la dependencia observada entre S y G se debe a una conexión causal o es espuria (dependencia aparente que surge de una causa común, R ). (ver la paradoja de Simpson )
Para determinar si una relación causal se identifica a partir de una red bayesiana arbitraria con variables no observadas, se pueden usar las tres reglas de " do -calculus" [1] [4] y probar si todos los términos do pueden eliminarse de la expresión de esa relación , confirmando así que la cantidad deseada se puede estimar a partir de los datos de frecuencia. [5]
El uso de una red bayesiana puede ahorrar una cantidad considerable de memoria en comparación con tablas de probabilidad exhaustivas, si las dependencias en la distribución conjunta son escasas. Por ejemplo, una forma ingenua de almacenar las probabilidades condicionales de 10 variables de dos valores como una tabla requiere espacio de almacenamiento paravalores. Si la distribución local de ninguna variable depende de más de tres variables principales, la representación de la red bayesiana almacena como máximo valores.


Una ventaja de las redes bayesianas es que es intuitivamente más fácil para un ser humano comprender (un conjunto escaso de) las dependencias directas y las distribuciones locales que las distribuciones conjuntas completas.
Inferencia y aprendizaje
Las redes bayesianas realizan tres tareas principales de inferencia:
Inferir variables no observadas
Dado que una red bayesiana es un modelo completo de sus variables y sus relaciones, se puede utilizar para responder consultas probabilísticas sobre ellas. Por ejemplo, la red se puede utilizar para actualizar el conocimiento del estado de un subconjunto de variables cuando se observan otras variables (las variables de evidencia ). Este proceso de calcular la distribución posterior de las variables dada la evidencia se llama inferencia probabilística. El posterior proporciona una estadística suficiente universal para aplicaciones de detección, al elegir valores para el subconjunto de variables que minimizan alguna función de pérdida esperada, por ejemplo, la probabilidad de error de decisión. Por tanto, una red bayesiana puede considerarse un mecanismo para aplicar automáticamente el teorema de Bayes a problemas complejos.
Los métodos de inferencia exacta más comunes son: eliminación de variables , que elimina (por integración o suma) las variables no observadas que no son de consulta una por una distribuyendo la suma sobre el producto; la propagación del árbol de clique , que almacena en caché el cálculo para que se puedan consultar muchas variables a la vez y se puedan propagar nuevas pruebas rápidamente; y el condicionamiento recursivo y la búsqueda Y / O, que permiten una compensación de espacio-tiempo y igualan la eficiencia de la eliminación de variables cuando se usa suficiente espacio. Todos estos métodos tienen una complejidad exponencial en el ancho del árbol de la red . Los algoritmos de inferencia aproximada más comunes son el muestreo de importancia , estocásticoSimulación de MCMC , eliminación de mini cubos, propagación de creencias descabelladas , propagación de creencias generalizadas y métodos variacionales .
Aprendizaje de parámetros
Para especificar completamente la red bayesiana y, por lo tanto, representar completamente la distribución de probabilidad conjunta , es necesario especificar para cada nodo X la distribución de probabilidad de X condicionada a los padres de X. La distribución de X condicionada a sus padres puede tener cualquier forma. Es común trabajar con distribuciones discretas o gaussianas ya que eso simplifica los cálculos. A veces, solo se conocen las limitaciones de una distribución; entonces se puede usar el principio de máxima entropía para determinar una sola distribución, la que tiene la mayor entropía dadas las restricciones. (Análogamente, en el contexto específico de unred bayesiana dinámica , la distribución condicional para la evolución temporal del estado oculto se especifica comúnmente para maximizar la tasa de entropía del proceso estocástico implícito).
A menudo, estas distribuciones condicionales incluyen parámetros que se desconocen y deben estimarse a partir de datos, por ejemplo, mediante el enfoque de máxima verosimilitud . La maximización directa de la probabilidad (o de la probabilidad posterior ) es a menudo compleja dadas las variables no observadas. Un enfoque clásico de este problema es el algoritmo de maximización de expectativas , que alterna el cálculo de los valores esperados de las variables no observadas condicionadas a los datos observados, con la maximización de la probabilidad completa (o posterior) asumiendo que los valores esperados previamente calculados son correctos. En condiciones de regularidad leve, este proceso converge en valores de máxima verosimilitud (o máximo posterior) para los parámetros.
Un enfoque más completamente bayesiano de los parámetros es tratarlos como variables adicionales no observadas y calcular una distribución posterior completa sobre todos los nodos condicionada a los datos observados, y luego integrar los parámetros. Este enfoque puede ser costoso y conducir a modelos de grandes dimensiones, lo que hace que los enfoques clásicos de establecimiento de parámetros sean más manejables.
Aprendizaje estructurado
En el caso más simple, un experto especifica una red bayesiana y luego se utiliza para realizar inferencias. En otras aplicaciones, la tarea de definir la red es demasiado compleja para los humanos. En este caso, la estructura de la red y los parámetros de las distribuciones locales deben aprenderse a partir de los datos.
El aprendizaje automático de la estructura gráfica de una red bayesiana (BN) es un desafío perseguido dentro del aprendizaje automático . La idea básica se remonta a un algoritmo de recuperación desarrollado por Rebane y Pearl [6] y se basa en la distinción entre los tres patrones posibles permitidos en un DAG de 3 nodos:
| Patrón | Modelo |
|---|---|
| Cadena | |
| Tenedor | |
| Colisionador |



Los primeros 2 representan las mismas dependencias ( y son independientes dados ) y son, por tanto, indistinguibles. El colisionador, sin embargo, se puede identificar de forma única, ya que y son marginalmente independientes y todos los demás pares son dependientes. Por lo tanto, mientras que los esqueletos (los gráficos sin flechas) de estos tres tripletes son idénticos, la direccionalidad de las flechas es parcialmente identificable. La misma distinción se aplica cuando y tener padres comunes, excepto que primero se debe condicionar a esos padres. Se han desarrollado algoritmos para determinar sistemáticamente el esqueleto del gráfico subyacente y, luego, orientar todas las flechas cuya direccionalidad está dictada por las independientes condicionales observadas. [1] [7] [8] [9]



Un método alternativo de aprendizaje estructural utiliza la búsqueda basada en optimización. Requiere una función de puntuación y una estrategia de búsqueda. Una función de puntuación común es la probabilidad posterior de la estructura dada los datos de entrenamiento, como el BIC o el BDeu. El requisito de tiempo de una búsqueda exhaustiva que devuelve una estructura que maximiza la puntuación es superexponencial en el número de variables. Una estrategia de búsqueda local realiza cambios incrementales destinados a mejorar la puntuación de la estructura. Un algoritmo de búsqueda global como la cadena de Markov Monte Carlo puede evitar quedar atrapado en mínimos locales . Friedman y col. [10] [11] discutir el usoinformación mutua entre variables y búsqueda de una estructura que la maximice. Lo hacen restringiendo el conjunto candidato principal a k nodos y buscando exhaustivamente en él.
Un método particularmente rápido para el aprendizaje exacto de BN consiste en plantear el problema como un problema de optimización y resolverlo mediante la programación de enteros . Las restricciones de aciclicidad se agregan al programa entero (IP) durante la resolución en forma de planos de corte . [12] Este método puede manejar problemas con hasta 100 variables.
Para hacer frente a problemas con miles de variables, es necesario un enfoque diferente. Una es probar primero un pedido y luego encontrar la estructura BN óptima con respecto a ese pedido. Esto implica trabajar en el espacio de búsqueda de los posibles ordenamientos, lo cual es conveniente por ser más pequeño que el espacio de las estructuras de la red. A continuación, se muestrean y evalúan varios pedidos. Se ha demostrado que este método es el mejor disponible en la literatura cuando el número de variables es enorme. [13]
Otro método consiste en enfocarse en la subclase de modelos descomponibles, para los cuales los MLE tienen una forma cerrada. Entonces es posible descubrir una estructura consistente para cientos de variables. [14]
El aprendizaje de las redes bayesianas con un ancho de árbol limitado es necesario para permitir una inferencia exacta y manejable, ya que la complejidad de la inferencia en el peor de los casos es exponencial en el ancho del árbol k (según la hipótesis del tiempo exponencial). Sin embargo, como propiedad global del gráfico, aumenta considerablemente la dificultad del proceso de aprendizaje. En este contexto, es posible utilizar K-tree para un aprendizaje eficaz. [15]
Introducción estadística
Datos dados y parámetro , un análisis bayesiano simple comienza con una probabilidad previa ( previa )y probabilidad para calcular una probabilidad posterior .





A menudo el anterior en depende a su vez de otros parámetros que no se mencionan en la probabilidad. Entonces, el anterior debe ser reemplazado por una probabilidad , y un previo en los parámetros recién introducidos es necesario, lo que da como resultado una probabilidad posterior




Este es el ejemplo más simple de un modelo de Bayes jerárquico . [ aclaración necesaria ]
El proceso puede repetirse; por ejemplo, los parámetros puede depender a su vez de parámetros adicionales , que requieren su propia previa. Finalmente, el proceso debe terminar, con antecedentes que no dependen de parámetros no mencionados.

Ejemplos introductorios
Dadas las cantidades medidas cada uno con errores distribuidos normalmente de desviación estándar conocida ,



Suponga que estamos interesados en estimar la . Un enfoque sería estimar lautilizando un enfoque de máxima verosimilitud ; dado que las observaciones son independientes, la probabilidad se factoriza y la estimación de máxima verosimilitud es simplemente


Sin embargo, si las cantidades están relacionadas, de modo que, por ejemplo, el individuo se han extraído de una distribución subyacente, entonces esta relación destruye la independencia y sugiere un modelo más complejo, por ejemplo,


con antecedentes inapropiados , . Cuándo, este es un modelo identificado (es decir, existe una solución única para los parámetros del modelo), y las distribuciones posteriores del individuotenderá a moverse, o encogerse lejos de las estimaciones de máxima verosimilitud hacia su media común. Esta contracción es un comportamiento típico en los modelos jerárquicos de Bayes.



Restricciones sobre antecedentes
Se necesita algo de cuidado al elegir a priori en un modelo jerárquico, particularmente en variables de escala en niveles más altos de la jerarquía, como la variable en el ejemplo. Los anteriores habituales, como el anterior de Jeffreys, a menudo no funcionan, porque la distribución posterior no será normalizable y las estimaciones realizadas minimizando la pérdida esperada serán inadmisibles .

Definiciones y conceptos
Se han ofrecido varias definiciones equivalentes de una red bayesiana. Para lo siguiente, deje que G = ( V , E ) un gráfico acíclico dirigido (DAG) y dejar que X = ( X v ), v ∈ V ser un conjunto de variables aleatorias indexadas por V .
Definición de factorización
X es una red bayesiana con respecto a G si su función de densidad de probabilidad conjunta (con respecto a una medida de producto ) se puede escribir como un producto de las funciones de densidad individuales, condicional a sus variables madre: [16]

donde pa ( v ) es el conjunto de padres de v (es decir, aquellos vértices que apuntan directamente a v a través de un solo borde).
Para cualquier conjunto de variables aleatorias, la probabilidad de cualquier miembro de una distribución conjunta se puede calcular a partir de probabilidades condicionales utilizando la regla de la cadena (dado un orden topológico de X ) de la siguiente manera: [16]

Usando la definición anterior, esto se puede escribir como:

La diferencia entre las dos expresiones es la independencia condicional de las variables de cualquiera de sus no descendientes, dados los valores de sus variables padre.
Propiedad local de Markov
X es una red bayesiana con respecto a G si satisface la propiedad local de Markov : cada variable es condicionalmente independiente de sus no descendientes dadas sus variables principales: [17]

donde de ( v ) es el conjunto de descendientes y V \ de ( v ) es el conjunto de no descendientes de v .
Esto se puede expresar en términos similares a la primera definición, como
![{\ Displaystyle {\ begin {alineado} & \ operatorname {P} (X_ {v} = x_ {v} \ mid X_ {i} = x_ {i} {\ text {para cada}} X_ {i} {\ text {que no es descendiente de}} X_ {v} \,) \\ [6pt] = {} & P (X_ {v} = x_ {v} \ mid X_ {j} = x_ {j} {\ text {para cada}} X_ {j} {\ text {que es un padre de}} X_ {v} \,) \ end {alineado}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f8f18a3121835ff1e58881ebfc0d5f8ef95b783d)
El conjunto de padres es un subconjunto del conjunto de no descendientes porque el gráfico es acíclico .
Desarrollo de redes bayesianas
El desarrollo de una red bayesiana a menudo comienza con la creación de un DAG G tal que X satisface la propiedad de Markov locales con respecto a G . A veces, este es un DAG causal . Se evalúan las distribuciones de probabilidad condicional de cada variable dados sus padres en G. En muchos casos, en particular en el caso en el que las variables son discretas, si la distribución conjunta de X es el producto de estas distribuciones condicionales, entonces X es una red bayesiana con respecto a G . [18]
Manta de Markov
El manto de Markov de un nodo es el conjunto de nodos que consta de sus padres, sus hijos y cualquier otro padre de sus hijos. La manta de Markov hace que el nodo sea independiente del resto de la red; la distribución conjunta de las variables en el manto de Markov de un nodo es conocimiento suficiente para calcular la distribución del nodo. X es una red bayesiana con respecto a G si cada nodo es condicionalmente independiente de todos los demás nodos de la red, dado su manto de Markov . [17]
d -separación
Esta definición puede hacerse más general definiendo la "d" -separación de dos nodos, donde d significa direccional. [1] Primero definimos la separación "d" de un camino y luego definiremos la separación "d" de dos nodos en términos de eso.
Sea P un camino desde el nodo u hasta v . Un camino es un camino sin bucles, no dirigido (es decir, se ignoran todas las direcciones de los bordes) entre dos nodos. Entonces P se dice que es d -separado por un conjunto de nodos de Z si cualquiera de las condiciones siguientes bodegas:
- P contiene (pero no necesita ser completamente) una cadena dirigida, o , de manera que el nodo medio m está en Z ,
- P contiene un tenedor,, de manera que el nodo medio m está en Z , o
- P contiene una bifurcación invertida (o colisionador),, De manera que el medio nodo m no está en Z y no descendiente de m está en Z .




Los nodos u y v son d Separados por Z si todos los caminos entre ellos son d Separado. Si u y v no están separados-d, que están conectados-d.
X es una red bayesiana con respecto a G si, para dos nodos cualesquiera u , v :

donde Z es un conjunto que d desconectadores u y v . (La manta Markov es el conjunto mínimo de nodos que d desconectadores nodo v de todos los otros nodos.)
Redes causales
Aunque las redes bayesianas se utilizan a menudo para representar relaciones causales , no es necesario que sea así: un borde dirigido de u a v no requiere que X v sea causalmente dependiente de X u . Esto se demuestra por el hecho de que las redes bayesianas en los gráficos:

son equivalentes: es decir, imponen exactamente los mismos requisitos de independencia condicional.
Una red causal es una red bayesiana con el requisito de que las relaciones sean causales. La semántica adicional de las redes causales especifica que si se provoca activamente que un nodo X esté en un estado x dado (una acción escrita como do ( X = x )), entonces la función de densidad de probabilidad cambia a la de la red obtenida al cortar el enlaces de los padres de X a X , y estableciendo X en el valor causado x . [1] Utilizando esta semántica, se puede predecir el impacto de las intervenciones externas a partir de los datos obtenidos antes de la intervención.
Inferencia de complejidad y algoritmos de aproximación
En 1990, mientras trabajaba en la Universidad de Stanford en grandes aplicaciones bioinformáticas, Cooper demostró que la inferencia exacta en redes bayesianas es NP-difícil . [19] Este resultado impulsó la investigación sobre algoritmos de aproximación con el objetivo de desarrollar una aproximación manejable a la inferencia probabilística. En 1993, Paul Dagum y Michael Luby demostraron dos resultados sorprendentes sobre la complejidad de la aproximación de la inferencia probabilística en redes bayesianas. [20] Primero, demostraron que ningún algoritmo determinista manejable puede aproximar la inferencia probabilística dentro de un error absoluto ɛ <1/2. En segundo lugar, demostraron que ningúnEl algoritmo aleatorio puede aproximar la inferencia probabilística dentro de un error absoluto ɛ <1/2 con una probabilidad de confianza mayor que 1/2.
Aproximadamente al mismo tiempo, Roth demostró que la inferencia exacta en las redes bayesianas es de hecho # P-completo (y, por lo tanto, tan difícil como contar el número de asignaciones satisfactorias de una fórmula de forma normal conjuntiva (CNF) y esa inferencia aproximada dentro de un factor 2 n 1− ɛ para cada ɛ > 0, incluso para redes bayesianas con arquitectura restringida, es NP-hard. [21] [22]
En términos prácticos, estos resultados de complejidad sugirieron que, si bien las redes bayesianas eran representaciones ricas para las aplicaciones de aprendizaje automático y de inteligencia artificial, su uso en grandes aplicaciones del mundo real tendría que ser moderado por restricciones estructurales topológicas, como las redes Bayes ingenuas, o por restricciones. en las probabilidades condicionales. El algoritmo de varianza acotada [23] desarrollado por Dagum y Luby fue el primer algoritmo de aproximación rápida demostrable para aproximar de manera eficiente la inferencia probabilística en redes bayesianas con garantías en la aproximación del error. Este poderoso algoritmo requería que la restricción menor en las probabilidades condicionales de la red bayesiana se limitara a cero y uno por 1 / p (n ) donde p ( n ) era cualquier polinomio sobre el número de nodos de la red n .
Software
El software notable para redes bayesianas incluye:
- Solo otra muestra de Gibbs (JAGS): alternativa de código abierto a WinBUGS. Utiliza muestreo de Gibbs.
- OpenBUGS : desarrollo de código abierto de WinBUGS.
- SPSS Modeler : software comercial que incluye una implementación para redes bayesianas.
- Stan (software) : Stan es un paquete de código abierto para obtener inferencias bayesianas utilizando el muestreador No-U-Turn (NUTS), [24] una variante del Hamiltoniano Monte Carlo.
- PyMC3 : una biblioteca de Python que implementa un lenguaje específico de dominio integrado para representar redes bayesianas y una variedad de muestreadores (incluido NUTS)
- BNLearn : una biblioteca de Python con más capacidades y permite la expansión de una red bayesiana regular.
- WinBUGS : una de las primeras implementaciones computacionales de muestreadores MCMC. Ya no se mantiene.
Historia
El término red bayesiana fue acuñado por Judea Pearl en 1985 para enfatizar: [25]
- la naturaleza a menudo subjetiva de la información de entrada
- la dependencia del condicionamiento de Bayes como base para actualizar la información
- la distinción entre modos de razonamiento causal y probatorio [26]
A finales de la década de 1980, Pearl's Probabilistic Reasoning in Intelligent Systems [27] y Naapolitan 's Probabilistic Reasoning in Expert Systems [28] resumieron sus propiedades y las establecieron como un campo de estudio.
Ver también
- Epistemología bayesiana
- Programación bayesiana
- Inferencia causal
- Diagrama de bucle causal
- Árbol de Chow – Liu
- Inteligencia Computacional
- Filogenética computacional
- Red de creencias profundas
- Teoría de Dempster-Shafer : una generalización del teorema de Bayes
- Algoritmo de maximización de expectativas
- Gráfico de factores
- Memoria temporal jerárquica
- Filtro de Kalman
- Marco de predicción de memoria
- Distribución de la mezcla
- Modelo de mezcla
- Clasificador ingenuo de Bayes
- Polytree
- Fusión de sensores
- Alineación de secuencia
- Modelos de ecuaciones estructurales
- Lógica subjetiva
- Red bayesiana de orden variable
Notas
- ↑ a b c d e Pearl, Judea (2000). Causalidad: modelos, razonamiento e inferencia . Prensa de la Universidad de Cambridge . ISBN 978-0-521-77362-1. OCLC 42291253 .
- ^ "El criterio de la puerta trasera" (PDF) . Consultado el 18 de septiembre de 2014 .
- ^ "D-Separación sin lágrimas" (PDF) . Consultado el 18 de septiembre de 2014 .
- ^ Perla J (1994). "Un cálculo probabilístico de acciones" . En Lopez de Mantaras R, Poole D (eds.). AUI'94 Actas de la Décima Conferencia Internacional sobre Incertidumbre en Inteligencia Artificial . San Mateo CA: Morgan Kaufmann . págs. 454–462. arXiv : 1302.6835 . Código bibliográfico : 2013arXiv1302.6835P . ISBN 1-55860-332-8.
- ^ Shpitser I, Pearl J (2006). "Identificación de distribuciones intervencionistas condicionales". En Dechter R, Richardson TS (eds.). Actas de la Vigésima Segunda Conferencia sobre Incertidumbre en Inteligencia Artificial . Corvallis, OR: AUAI Press. págs. 437–444. arXiv : 1206.6876 .
- ^ Rebane G, Pearl J (1987). "La recuperación de poliarboles causales a partir de datos estadísticos". Actas, 3er Taller sobre Incertidumbre en IA . Seattle, WA. págs. 222–228. arXiv : 1304.2736 .
- ^ Bebidas espirituosas P, Glymour C (1991). "Un algoritmo para la recuperación rápida de gráficos causales dispersos" (PDF) . Revisión informática de ciencias sociales . 9 (1): 62–72. doi : 10.1177 / 089443939100900106 . S2CID 38398322 .
- ^ Spirtes P, Glymour CN, Scheines R (1993). Causalidad, predicción y búsqueda (1ª ed.). Springer-Verlag. ISBN 978-0-387-97979-3.
- ^ Verma T, Pearl J (1991). "Equivalencia y síntesis de modelos causales" . En Bonissone P, Henrion M, Kanal LN, Lemmer JF (eds.). AUI '90 Actas de la Sexta Conferencia Anual sobre Incertidumbre en Inteligencia Artificial . Elsevier. págs. 255–270. ISBN 0-444-89264-8.
- ^ Friedman N, Geiger D, Goldszmidt M (noviembre de 1997). "Clasificadores de red bayesiana" . Aprendizaje automático . 29 (2-3): 131-163. doi : 10.1023 / A: 1007465528199 .
- ^ Friedman N, Linial M, Nachman I, Pe'er D (agosto de 2000). "Uso de redes bayesianas para analizar datos de expresión". Revista de Biología Computacional . 7 (3–4): 601–20. CiteSeerX 10.1.1.191.139 . doi : 10.1089 / 106652700750050961 . PMID 11108481 .
- ^ Cussens J (2011). "Aprendizaje en red bayesiana con planos de corte" (PDF) . Actas de la 27ª Conferencia Anual de la Conferencia sobre Incertidumbre en Inteligencia Artificial : 153–160. arXiv : 1202.3713 . Código bibliográfico : 2012arXiv1202.3713C .
- ^ Scanagatta M, de Campos CP, Corani G, Zaffalon M (2015). "Aprendizaje de redes bayesianas con miles de variables" . NIPS-15: Avances en sistemas de procesamiento de información neuronal . 28 . Asociados Curran. págs. 1855–1863.
- ^ Petitjean F, Webb GI, Nicholson AE (2013). Escalado del análisis log-lineal a datos de alta dimensión (PDF) . Congreso Internacional de Minería de Datos. Dallas, TX, Estados Unidos: IEEE.
- ^ M. Scanagatta, G. Corani, CP de Campos y M. Zaffalon. Aprendizaje de redes bayesianas limitadas por ancho de árbol con miles de variables. En NIPS-16: Avances en sistemas de procesamiento de información neuronal 29, 2016.
- ↑ a b Russell y Norvig , 2003 , p. 496.
- ↑ a b Russell y Norvig , 2003 , p. 499.
- ^ Napolitano RE (2004). Aprendizaje de redes bayesianas . Prentice Hall. ISBN 978-0-13-012534-7.
- ^ Cooper GF (1990). "La complejidad computacional de la inferencia probabilística utilizando redes de creencias bayesianas" (PDF) . Inteligencia artificial . 42 (2–3): 393–405. doi : 10.1016 / 0004-3702 (90) 90060-d .
- ^ Dagum P , Luby M (1993). "Aproximación de la inferencia probabilística en las redes de creencias bayesianas es NP-difícil". Inteligencia artificial . 60 (1): 141-153. CiteSeerX 10.1.1.333.1586 . doi : 10.1016 / 0004-3702 (93) 90036-b .
- ^ D. Roth, Sobre la dureza del razonamiento aproximado , IJCAI (1993)
- ^ D. Roth, Sobre la dureza del razonamiento aproximado , Inteligencia artificial (1996)
- ^ Dagum P , Luby M (1997). "Un algoritmo de aproximación óptimo para la inferencia bayesiana" . Inteligencia artificial . 93 (1–2): 1–27. CiteSeerX 10.1.1.36.7946 . doi : 10.1016 / s0004-3702 (97) 00013-1 . Archivado desde el original el 6 de julio de 2017 . Consultado el 19 de diciembre de 2015 .
- ^ Hoffman, Matthew D .; Gelman, Andrew (2011). "El muestreador sin giro en U: ajuste adaptativo longitudes de ruta en Hamiltonian Monte Carlo". arXiv : 1111.4246 . Código bibliográfico : 2011arXiv1111.4246H . Cite journal requiere
|journal=( ayuda ) - ^ Perla J (1985). Redes bayesianas: un modelo de memoria autoactivada para el razonamiento probatorio (Informe técnico de UCLA CSD-850017) . Actas de la 7ma Conferencia de la Sociedad de Ciencias Cognitivas, Universidad de California, Irvine, CA. págs. 329–334 . Consultado el 1 de mayo de 2009 .
- ^ Bayes T , Precio (1763). "Un ensayo para resolver un problema en la doctrina de las posibilidades" . Transacciones filosóficas de la Royal Society . 53 : 370–418. doi : 10.1098 / rstl.1763.0053 .
- ↑ Pearl J (15 de septiembre de 1988). Razonamiento probabilístico en sistemas inteligentes . San Francisco CA: Morgan Kaufmann . pag. 1988. ISBN 978-1558604797.
- ^ Napolitano RE (1989). Razonamiento probabilístico en sistemas expertos: teoría y algoritmos . Wiley. ISBN 978-0-471-61840-9.
Referencias
- Ben Gal I (2007). "Redes Bayesianas" (PDF) . En Ruggeri F, Kennett RS, Faltin FW (eds.). Página de soporte . Enciclopedia de Estadística en Calidad y Fiabilidad . John Wiley e hijos . doi : 10.1002 / 9780470061572.eqr089 . ISBN 978-0-470-01861-3.
- Bertsch McGrayne S (2011). La teoría que no moriría . New Haven: Prensa de la Universidad de Yale .
- Borgelt C, Kruse R (marzo de 2002). Modelos gráficos: métodos de análisis de datos y minería . Chichester, Reino Unido : Wiley . ISBN 978-0-470-84337-6.
- Borsuk ME (2008). "Informática ecológica: redes bayesianas". En Jørgensen, Sven Erik , Fath, Brian (eds.). Enciclopedia de Ecología . Elsevier. ISBN 978-0-444-52033-3.
- Castillo E, Gutiérrez JM, Hadi AS (1997). "Aprendizaje de redes bayesianas". Sistemas expertos y modelos de redes probabilísticas . Monografías en informática. Nueva York: Springer-Verlag . págs. 481–528. ISBN 978-0-387-94858-4.
- Comley JW, Dowe DL (junio de 2003). "Redes bayesianas generales y lenguajes asimétricos" . Actas de la 2da Conferencia Internacional de Hawai sobre Estadísticas y Campos Relacionados .
- Comley JW, Dowe DL (2005). "Longitud mínima de mensaje y redes bayesianas generalizadas con lenguajes asimétricos" . En Grünwald PD, Myung IJ, Pitt MA (eds.). Avances en Longitud Mínima de Descripción: Teoría y Aplicaciones . Serie de procesamiento de información neuronal. Cambridge, Massachusetts : Bradford Books ( MIT Press ) (publicado en abril de 2005). págs. 265-294. ISBN 978-0-262-07262-5.(Este documento coloca árboles de decisión en los nodos internos de las redes Bayes utilizando la Longitud mínima de mensaje ( MML ).
- Darwiche A (2009). Modelado y razonamiento con redes bayesianas . Prensa de la Universidad de Cambridge . ISBN 978-0521884389.
- Dowe, David L. (31 de mayo de 2011). "Modelos gráficos de red bayesiana híbrida, consistencia estadística, invariancia y unicidad" (PDF) . Filosofía de la Estadística . Elsevier. págs. 901–982 . ISBN 9780080930961.
- Fenton N, Neil ME (noviembre de 2007). "Gestión de riesgos en el mundo moderno: aplicaciones de redes bayesianas" (PDF) . Un informe de transferencia de conocimientos de la London Mathematical Society y la Red de transferencia de conocimientos para las matemáticas industriales . Londres (Inglaterra) : London Mathematical Society . Archivado desde el original (PDF) el 14 de mayo de 2008 . Consultado el 29 de octubre de 2008 .
- Fenton N, Neil ME (23 de julio de 2004). "Combinación de evidencia en el análisis de riesgos utilizando redes bayesianas" (PDF) . Boletín del Club de sistemas críticos de seguridad . 13 (4). Newcastle upon Tyne , Inglaterra. págs. 8-13. Archivado desde el original (PDF) el 27 de septiembre de 2007.
- Gelman A, Carlin JB, Stern HS, Rubin DB (2003). "Parte II: Fundamentos del análisis de datos bayesianos: modelos jerárquicos Ch.5" . Análisis de datos bayesianos . Prensa CRC . págs. 120–. ISBN 978-1-58488-388-3.
- Heckerman, David (1 de marzo de 1995). "Tutorial de aprendizaje con redes bayesianas" . En Jordan, Michael Irwin (ed.). Aprendizaje en modelos gráficos . Computación adaptativa y aprendizaje automático. Cambridge, Massachusetts : MIT Press (publicado en 1998). págs. 301–354. ISBN 978-0-262-60032-3. Archivado desde el original el 19 de julio de 2006 . Consultado el 15 de septiembre de 2006 .CS1 maint: bot: estado de URL original desconocido ( enlace ): También aparece como Heckerman, David (marzo de 1997). "Redes Bayesianas para Minería de Datos". Minería de datos y descubrimiento de conocimientos . 1 (1): 79-119. doi : 10.1023 / A: 1009730122752 . S2CID 6294315 .
- Una versión anterior aparece como Microsoft Research , 1 de marzo de 1995. El artículo trata sobre el aprendizaje tanto de parámetros como de estructuras en redes bayesianas.
- Jensen FV, Nielsen TD (6 de junio de 2007). Redes bayesianas y gráficos de decisión . Serie de Ciencias de la Información y Estadística (2ª ed.). Nueva York : Springer-Verlag . ISBN 978-0-387-68281-5.
- Karimi K, Hamilton HJ (2000). "Encontrar relaciones temporales: redes bayesianas causales frente a C4. 5" (PDF) . Duodécimo Simposio Internacional de Metodologías para Sistemas Inteligentes .
- Korb KB, Nicholson AE (diciembre de 2010). Inteligencia artificial bayesiana . CRC Ciencias de la Computación y Análisis de Datos (2ª ed.). Chapman & Hall ( CRC Press ). doi : 10.1007 / s10044-004-0214-5 . ISBN 978-1-58488-387-6. S2CID 22138783 .
- Lunn D, Spiegelhalter D, Thomas A, Best N (noviembre de 2009). "El proyecto BUGS: evolución, crítica y direcciones futuras". Estadística en Medicina . 28 (25): 3049–67. doi : 10.1002 / sim.3680 . PMID 19630097 .
- Neil M, Fenton N, Tailor M (agosto de 2005). Greenberg, Michael R. (ed.). "Uso de redes bayesianas para modelar pérdidas operativas esperadas e inesperadas" (PDF) . Análisis de riesgo . 25 (4): 963–72. doi : 10.1111 / j.1539-6924.2005.00641.x . PMID 16268944 . S2CID 3254505 .
- Pearl J (septiembre de 1986). "Fusión, propagación y estructuración en redes de creencias". Inteligencia artificial . 29 (3): 241–288. doi : 10.1016 / 0004-3702 (86) 90072-X .
- Pearl J (1988). Razonamiento probabilístico en sistemas inteligentes: redes de inferencia plausible . Serie Representación y Razonamiento (2ª edición). San Francisco, California : Morgan Kaufmann . ISBN 978-0-934613-73-6.
- Pearl J , Russell S (noviembre de 2002). "Redes Bayesianas". En Arbib MA (ed.). Manual de teoría del cerebro y redes neuronales . Cambridge, Massachusetts : Bradford Books ( MIT Press ). págs. 157–160. ISBN 978-0-262-01197-6.
- Russell, Stuart J .; Norvig, Peter (2003), Inteligencia artificial: un enfoque moderno (2a ed.), Upper Saddle River, Nueva Jersey: Prentice Hall, ISBN 0-13-790395-2.
- Zhang NL, Poole D (mayo de 1994). "Un enfoque simple para los cálculos de redes bayesianas" (PDF) . Actas de la Décima Conferencia Bienal Canadiense de Inteligencia Artificial (AI-94). : 171–178. Este artículo presenta la eliminación de variables para las redes de creencias.
Lectura adicional
- Conrady S, Jouffe L (1 de julio de 2015). Bayesian Networks y BayesiaLab: una introducción práctica para investigadores . Franklin, Tennessee: Estados Unidos bayesianos. ISBN 978-0-9965333-0-0.
- Charniak E (invierno de 1991). "Redes bayesianas sin lágrimas" (PDF) . Revista AI .
- Kruse R, Borgelt C, Klawonn F, Moewes C, Steinbrecher M, Held P (2013). Inteligencia Computacional Una Introducción Metodológica . Londres: Springer-Verlag. ISBN 978-1-4471-5012-1.
- Borgelt C, Steinbrecher M, Kruse R (2009). Modelos gráficos: representaciones para el aprendizaje, el razonamiento y la minería de datos (segunda ed.). Chichester: Wiley. ISBN 978-0-470-74956-2.
Enlaces externos
- Introducción a las redes bayesianas y sus aplicaciones contemporáneas
- Tutorial on-line sobre redes bayesianas y probabilidad
- Web-App para crear redes bayesianas y ejecutarla con un método Monte Carlo
- Redes bayesianas de tiempo continuo
- Redes bayesianas: explicación y analogía
- Un tutorial en vivo sobre el aprendizaje de las redes bayesianas
- Un modelo de Bayes jerárquico para manejar la heterogeneidad de la muestra en problemas de clasificación , proporciona un modelo de clasificación que toma en consideración la incertidumbre asociada con la medición de muestras replicadas.
- Modelo jerárquico ingenuo de Bayes para manejar la incertidumbre de la muestra Archivado el 28 de septiembre de 2007 en Wayback Machine , muestra cómo realizar la clasificación y el aprendizaje con variables continuas y discretas con mediciones replicadas.