| Parte de una serie de estadísticas |
| Teoría de probabilidad |
|---|
 |
En la teoría de la probabilidad , el valor esperado de una variable aleatoria , a menudo denotado , , o , es una generalización del promedio ponderado , e intuitivamente es la media aritmética de un gran número de realizaciones independientes de. El operador de la expectativa también se estiliza comúnmente como o . [1] [2] [3] [4] El valor esperado también se conoce como expectativa , expectativa matemática , media , promedio o primer momento . El valor esperado es un concepto clave en economía , finanzas y muchas otras materias.


![\ operatorname {E} [X]](https://wikimedia.org/api/rest_v1/media/math/render/svg/44dd294aa33c0865f58e2b1bdaf44ebe911dbf93)




Por definición, el valor esperado de una variable aleatoria constante es . [5] El valor esperado de una variable aleatoriacon resultados equiprobables se define como la media aritmética de los términos Si algunas de las probabilidades de un resultado individual son desiguales, entonces el valor esperado se define como el promedio ponderado por probabilidad de la s, es decir, la suma de los productos . [6] El valor esperado de una variable aleatoria general implica la integración en el sentido de Lebesgue .








Historia
La idea del valor esperado se originó a mediados del siglo XVII a partir del estudio del llamado problema de los puntos , que busca dividir las apuestas de manera justa entre dos jugadores, que tienen que terminar su juego antes de que sea adecuadamente. terminado. [7] Este problema se había debatido durante siglos, y se habían sugerido muchas propuestas y soluciones contradictorias a lo largo de los años, cuando se lo planteó a Blaise Pascal el escritor y matemático aficionado francés Chevalier de Méré.en 1654. Méré afirmó que este problema no podía resolverse y que mostraba cuán defectuosas eran las matemáticas cuando se trataba de su aplicación al mundo real. Pascal, siendo matemático, estaba provocado y decidido a resolver el problema de una vez por todas.
Comenzó a discutir el problema en la famosa serie de cartas a Pierre de Fermat . Muy pronto, ambos encontraron una solución de forma independiente. Resolvieron el problema de diferentes formas computacionales, pero sus resultados fueron idénticos porque sus cálculos se basaron en el mismo principio fundamental. El principio es que el valor de una ganancia futura debe ser directamente proporcional a la posibilidad de obtenerla. Este principio parecía haber sido algo natural para ambos. Estaban muy complacidos por el hecho de que habían encontrado esencialmente la misma solución, y esto a su vez los hizo absolutamente convencidos de que habían resuelto el problema de manera concluyente; sin embargo, no publicaron sus hallazgos. Solo informaron al respecto a un pequeño círculo de amigos científicos mutuos en París. [8]
Tres años más tarde, en 1657, un matemático holandés Christiaan Huygens , que acababa de visitar París, publicó un tratado (véase Huygens (1657) ) " De ratiociniis in ludo aleæ " sobre teoría de la probabilidad. En este libro, consideró el problema de los puntos y presentó una solución basada en el mismo principio que las soluciones de Pascal y Fermat. Huygens también amplió el concepto de expectativa al agregar reglas sobre cómo calcular las expectativas en situaciones más complicadas que el problema original (por ejemplo, para tres o más jugadores). En este sentido, este libro puede verse como el primer intento exitoso de sentar las bases de la teoría de la probabilidad .
En el prólogo de su libro, Huygens escribió:
También hay que decir que desde hace algún tiempo algunos de los mejores matemáticos de Francia se han ocupado de este tipo de cálculo para que nadie me atribuya el honor de la primera invención. Esto no me pertenece. Pero estos sabios, aunque se pusieron a prueba proponiéndose entre sí muchas cuestiones difíciles de resolver, han ocultado sus métodos. Por lo tanto, he tenido que examinar y profundizar en este asunto comenzando por los elementos, y por eso me es imposible afirmar que incluso he comenzado por el mismo principio. Pero finalmente he descubierto que mis respuestas en muchos casos no difieren de las de ellos.
- Edwards (2002)
Así, Huygens se enteró del Problema de Méré en 1655 durante su visita a Francia; más tarde, en 1656, a partir de su correspondencia con Carcavi, se enteró de que su método era esencialmente el mismo que el de Pascal; de modo que antes de que su libro saliera a la imprenta en 1657, conocía la prioridad de Pascal en este tema.
A mediados del siglo XIX, Pafnuty Chebyshev se convirtió en la primera persona en pensar sistemáticamente en términos de las expectativas de las variables aleatorias . [9]
Etimología
Ni Pascal ni Huygens utilizaron el término "expectativa" en su sentido moderno. En particular, Huygens escribe: [10]
Que cualquier Oportunidad o Expectativa de ganar cualquier cosa vale tal Suma, como se obtendría en la misma Oportunidad y Expectativa en un momento justo. ... Si espero a o b, y tengo la misma probabilidad de obtenerlos, mi Expectativa vale (a + b) / 2.
Más de cien años después, en 1814, Pierre-Simon Laplace publicó su tratado " Théorie analytique des probabilités ", donde se definía explícitamente el concepto de valor esperado: [11]
… Esta ventaja en la teoría del azar es producto de la suma esperada por la probabilidad de obtenerla; es la suma parcial que debe resultar cuando no deseamos correr los riesgos del evento al suponer que la división se hace proporcional a las probabilidades. Esta división es la única equitativa cuando se eliminan todas las circunstancias extrañas; porque un grado igual de probabilidad da igual derecho a la suma esperada. A esta ventaja la llamaremos esperanza matemática .
Anotaciones
El uso de la letra para denotar el valor esperado se remonta a WA Whitworth en 1901. [12] El símbolo se ha vuelto popular desde entonces para los escritores ingleses. En alemán,significa "Erwartungswert", en español para "Esperanza matemática", y en francés para "Espérance mathématique". [13]

Cuando se usa E para denotar el valor esperado, los autores usan una variedad de notación: el operador de expectativa se puede esterilizar como (vertical), (cursiva), o (en negrita ), mientras que los corchetes (), corchetes (), o sin corchetes () se utilizan todos.

![EX]](https://wikimedia.org/api/rest_v1/media/math/render/svg/e455a34363c03fc5df8208d8b81fa29e3cdd524e)
Otra notación popular es , mientras que se usa comúnmente en física, y en la literatura en lengua rusa.



Definición
Caso finito
Dejar ser una variable aleatoria con un número finito de resultados finitos ocurriendo con probabilidades respectivamente. La expectativa dese define como [6]


![{\ Displaystyle \ operatorname {E} [X] = \ sum _ {i = 1} ^ {k} x_ {i} \, p_ {i} = x_ {1} p_ {1} + x_ {2} p_ { 2} + \ cdots + x_ {k} p_ {k}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/519542ccdb827d224e730020a1f0c0ce675297d3)
Ya que el valor esperado es la suma ponderada de la valores, con las probabilidades como los pesos.



Si todos los resultados son equiprobables (es decir,), entonces el promedio ponderado se convierte en el promedio simple . Por otro lado, si los resultados no son equiprobables, entonces el promedio simple debe ser reemplazado por el promedio ponderado, que toma en cuenta el hecho de que algunos resultados son más probables que otros.

Ejemplos
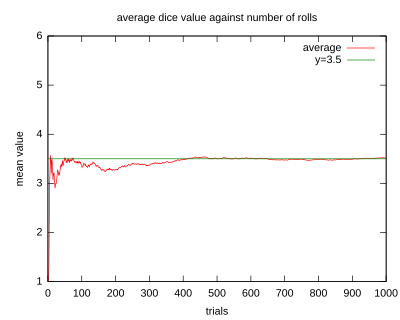
- Dejar representan el resultado de una tirada de un dado de seis caras . Más específicamente,será el número de pepitas que se muestran en la cara superior del dado después del lanzamiento. Los posibles valores para son 1, 2, 3, 4, 5 y 6, todos los cuales son igualmente probables con una probabilidad de 1/6. La expectativa de es
![{\ Displaystyle \ operatorname {E} [X] = 1 \ cdot {\ frac {1} {6}} + 2 \ cdot {\ frac {1} {6}} + 3 \ cdot {\ frac {1} { 6}} + 4 \ cdot {\ frac {1} {6}} + 5 \ cdot {\ frac {1} {6}} + 6 \ cdot {\ frac {1} {6}} = 3.5.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d535e1c37fd63db36fd0878e39b43ea7fa513ea4)
- Si uno lanza el dado veces y calcula el promedio (media aritmética ) de los resultados, luego comocrece, el promedio casi seguramente convergerá al valor esperado, un hecho conocido como la ley fuerte de los grandes números .
- El juego de la ruleta consiste en una pequeña bola y una rueda con 38 bolsillos numerados alrededor del borde. A medida que se hace girar la rueda, la bola rebota aleatoriamente hasta que se asienta en uno de los bolsillos. Suponga una variable aleatoriarepresenta el resultado (monetario) de una apuesta de $ 1 en un solo número (apuesta "directa"). Si la apuesta gana (lo que ocurre con probabilidad1/38en la ruleta americana), la recompensa es de $ 35; de lo contrario, el jugador pierde la apuesta. El beneficio esperado de tal apuesta será
![{\ Displaystyle \ operatorname {E} [\, {\ text {ganancia de}} \ $ 1 {\ text {bet}} \,] = - \ $ 1 \ cdot {\ frac {37} {38}} + \ $ 35 \ cdot {\ frac {1} {38}} = - \ $ {\ frac {1} {19}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/efa6df424d69a14b24a7b598b5e0f1e6e426bff1)
- Es decir, la apuesta de $ 1 se puede perder. , por lo que su valor esperado es


Caso contablemente infinito
Intuitivamente, la expectativa de una variable aleatoria que toma valores en un conjunto contable de resultados se define de manera análoga como la suma ponderada de los valores de los resultados, donde los pesos corresponden a las probabilidades de realizar ese valor. Sin embargo, los problemas de convergencia asociados con la suma infinita requieren una definición más cuidadosa. Una definición rigurosa primero define la expectativa de una variable aleatoria no negativa y luego la adapta a las variables aleatorias generales.
Dejar ser una variable aleatoria no negativa con un conjunto contable de resultados ocurriendo con probabilidades respectivamente. De manera análoga al caso discreto, el valor esperado de entonces se define como la serie


![{\ Displaystyle \ operatorname {E} [X] = \ sum _ {i = 1} ^ {\ infty} x_ {i} \, p_ {i}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2509d047fc89077d41febe60520c076d55386608)
Tenga en cuenta que desde , la suma infinita está bien definida y no depende del orden en que se calcula. A diferencia del caso finito, la expectativa aquí puede ser igual al infinito, si la suma infinita anterior aumenta sin límite.

Para una variable aleatoria general (no necesariamente no negativa) con un número contable de resultados, establezca y . Por definición,


![{\ Displaystyle \ operatorname {E} [X] = \ operatorname {E} [X ^ {+}] - \ operatorname {E} [X ^ {-}].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d54be7ea6dcbc06bf807cc33a18128131487a841)
Al igual que con las variables aleatorias no negativas, puede, una vez más, ser finito o infinito. La tercera opción aquí es queya no se garantiza que esté bien definido. Esto último sucede siempre que.
![{\ Displaystyle \ operatorname {E} [X ^ {+}] = \ operatorname {E} [X ^ {-}] = \ infty}](https://wikimedia.org/api/rest_v1/media/math/render/svg/39208448351df3073fb3667060ff9e29ed6156cc)
Ejemplos
- Suponer y por , donde (con siendo el logaritmo natural ) es el factor de escala tal que las probabilidades suman 1. Luego, usando la definición directa para variables aleatorias no negativas, tenemos





![{\ Displaystyle \ operatorname {E} [X] = \ sum _ {i} x_ {i} p_ {i} = 1 \ left ({\ frac {k} {2}} \ right) +2 \ left ({ \ frac {k} {8}} \ right) +3 \ left ({\ frac {k} {24}} \ right) + \ dots = {\ frac {k} {2}} + {\ frac {k } {4}} + {\ frac {k} {8}} + \ dots = k.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/080fb218bb6f48d69e19c8694dae679684ca1c15)
- Un ejemplo en el que la expectativa es infinita surge en el contexto de la paradoja de San Petersburgo . Dejar y por . Una vez más, dado que la variable aleatoria no es negativa, el cálculo del valor esperado da


![{\ Displaystyle \ operatorname {E} [X] = \ sum _ {i = 1} ^ {\ infty} x_ {i} \, p_ {i} = 2 \ cdot {\ frac {1} {2}} + 4 \ cdot {\ frac {1} {4}} + 8 \ cdot {\ frac {1} {8}} + 16 \ cdot {\ frac {1} {16}} + \ cdots = 1 + 1 + 1 +1+ \ cdots \, = \ infty.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7a04de85e01c5cc27e3e1635493583dd39c3fd38)
- Para un ejemplo donde la expectativa no está bien definida, suponga que la variable aleatoria toma valores con probabilidades respectivas , ..., donde es una constante de normalización que asegura que las probabilidades sumen uno.



- Entonces sigue que toma valor con probabilidad por y toma valor con probabilidad restante. Similar, toma valor con probabilidad por y toma valor con probabilidad restante. Usando la definición de variables aleatorias no negativas, se puede demostrar que tanto y (ver serie Armónica ). Por tanto, la expectativa de no está bien definido.








![{\ Displaystyle \ operatorname {E} [X ^ {+}] = \ infty}](https://wikimedia.org/api/rest_v1/media/math/render/svg/349709705912ec5400d727e0047361874e8af27e)
![{\ Displaystyle \ operatorname {E} [X ^ {-}] = \ infty}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4ac976e9034564f71b3627c8063ee2a0d3fbaff3)
Caso absolutamente continuo
Si es una variable aleatoria con una función de densidad de probabilidad de, entonces el valor esperado se define como la integral de Lebesgue

![{\ Displaystyle \ operatorname {E} [X] = \ int _ {\ mathbb {R}} xf (x) \, dx,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b6b4021050b825064c6e43aefc7694fb6307bc30)
donde los valores en ambos lados están bien definidos o no están bien definidos simultáneamente.
Ejemplo. Una variable aleatoria que tiene la distribución de Cauchy [14] tiene una función de densidad, pero el valor esperado no está definido ya que la distribución tiene grandes "colas" .
Caso general
En general, si es una variable aleatoria definida en un espacio de probabilidad , entonces el valor esperado de , denotado por , se define como la integral de Lebesgue

![{\ Displaystyle \ operatorname {E} [X] = \ int _ {\ Omega} X (\ omega) \, d \ operatorname {P} (\ omega).}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f2c4265bd78bfc615c6da1f1fae310d462793187)
Para las variables aleatorias multidimensionales, su valor esperado se define por componente. Eso es,
![{\ Displaystyle \ operatorname {E} [(X_ {1}, \ ldots, X_ {n})] = (\ operatorname {E} [X_ {1}], \ ldots, \ operatorname {E} [X_ {n }])}](https://wikimedia.org/api/rest_v1/media/math/render/svg/82529dea1fae623cf096f6e7955332fa73bf791a)
y, para una matriz aleatoria con elementos ,

![{\ Displaystyle (\ operatorname {E} [X]) _ {ij} = \ operatorname {E} [X_ {ij}].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5581856278a0f539aaa981d81fce64e5a35fff7a)
Propiedades básicas
Las propiedades básicas a continuación (y sus nombres en negrita) replican o siguen inmediatamente a las de la integral de Lebesgue . Tenga en cuenta que las letras "as" representan " casi con seguridad ", una propiedad central de la integral de Lebesgue. Básicamente, se dice que una desigualdad como es cierto casi con seguridad, cuando la medida de probabilidad atribuye masa cero al evento complementario .


- Para una variable aleatoria general , define como antes y , y tenga en cuenta que , con ambos y no negativo, entonces:

![{\ Displaystyle \ operatorname {E} [X] = {\ begin {cases} \ operatorname {E} [X ^ {+}] - \ operatorname {E} [X ^ {-}] & {\ text {if} } \ operatorname {E} [X ^ {+}] <\ infty {\ text {y}} \ operatorname {E} [X ^ {-}] <\ infty; \\\ infty & {\ text {if} } \ operatorname {E} [X ^ {+}] = \ infty {\ text {y}} \ operatorname {E} [X ^ {-}] <\ infty; \\ - \ infty & {\ text {if }} \ operatorname {E} [X ^ {+}] <\ infty {\ text {y}} \ operatorname {E} [X ^ {-}] = \ infty; \\ {\ text {undefined}} & {\ text {if}} \ operatorname {E} [X ^ {+}] = \ infty {\ text {y}} \ operatorname {E} [X ^ {-}] = \ infty. \ end {cases} }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c80257845a8fa7e82404f267002d9714dec21cd0)
- Dejar denotar la función indicadora de un evento , luego
- Fórmulas en términos de CDF: Sies la función de distribución acumulativa de la medida de probabilidad y es una variable aleatoria, entonces


![{\ Displaystyle \ operatorname {E} [{\ mathbf {1}} _ {A}] = 1 \ cdot \ operatorname {P} (A) +0 \ cdot \ operatorname {P} (\ Omega \ setminus A) = \ nombre de operador {P} (A).}](https://wikimedia.org/api/rest_v1/media/math/render/svg/49c23205ce0226e3a5e807040eea3ef1663e8542)


- donde los valores en ambos lados están bien definidos o no bien definidos simultáneamente, y la integral se toma en el sentido de Lebesgue-Stieltjes . Aquí, es la línea real extendida.
![{\ Displaystyle \ operatorname {E} [X] = \ int _ {\ overline {\ mathbb {R}}} x \, dF (x),}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8e2749d3c6bcc1ae1ec924cd1e0406f34a3c11e9)
![{\ Displaystyle {\ overline {\ mathbb {R}}} = [- \ infty, + \ infty]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/92df65c7a6de4a17db586e79121da6e9de7aaf17)
- Adicionalmente,
- con las integrales tomadas en el sentido de Lebesgue.
![{\ Displaystyle \ Displaystyle \ operatorname {E} [X] = \ int \ limits _ {0} ^ {\ infty} (1-F (x)) \, dx- \ int \ limits _ {- \ infty} ^ {0} F (x) \, dx,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e17ad7f7a7f00bc58379675c943ad21ee18120e8)
- Sigue la demostración de la segunda fórmula.
Prueba. For an arbitrary
The last equality holds because the fact that where implies that and hence Conversely, if where then and
The integrand in the above expression for is non-negative, so Tonelli's theorem applies, and the order of integration may be switched without altering the result. We have
Arguing as above,
and
Recalling that completes the proof.













- No negatividad: si (como entonces .
- Linealidad de la expectativa: [5] El operador de valor esperado (u operador de expectativa )es lineal en el sentido de que, para cualquier variable aleatoria y y una constante ,
![{\ Displaystyle \ operatorname {E} [X] \ geq 0}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cc359a5fbc4d9b691dceba58a5fd3cc7120cda15)
![\ operatorname {E} [\ cdot]](https://wikimedia.org/api/rest_v1/media/math/render/svg/0a71518eb57ffaf54c0c31bf94de5ac9d7ab11a1)


- siempre que el lado derecho esté bien definido. Esto significa que el valor esperado de la suma de cualquier número finito de variables aleatorias es la suma de los valores esperados de las variables aleatorias individuales, y el valor esperado se escala linealmente con una constante multiplicativa. Simbólicamente, para variables aleatorias y constantes , tenemos .
![{\ displaystyle {\ begin {alineado} \ operatorname {E} [X + Y] & = \ operatorname {E} [X] + \ operatorname {E} [Y], \\\ operatorname {E} [aX] & = un \ nombre de operador {E} [X], \ end {alineado}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3d3a0fa4f32e29c4cc4fd567a63afc384a7e3b91)



![{\ Displaystyle \ operatorname {E} [\ sum _ {i = 1} ^ {N} a_ {i} X_ {i}] = \ sum _ {i = 1} ^ {N} a_ {i} \ operatorname { E} [X_ {i}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7241a04578f5c026d83cb9ef2e78298ac465c2c3)
- Monotonicidad: Si (como) , y ambos y existir, entonces .

![{\ Displaystyle \ operatorname {E} [Y]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/639e8577c6faffc0471c7e123ead30970034e6d5)
![{\ Displaystyle \ operatorname {E} [X] \ leq \ operatorname {E} [Y]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bcc409f2b956425dc9dacce39207930f60057d55)
- La prueba se deriva de la propiedad de linealidad y no negatividad para , ya que (como).


- No multiplicatividad: en general, el valor esperado no es multiplicativo, es decir no es necesariamente igual a . Si y son independientes , entonces se puede demostrar que. Si las variables aleatorias son dependientes , generalmente, aunque en casos especiales de dependencia puede darse la igualdad.
- Ley del estadístico inconsciente : el valor esperado de una función medible de, , Dado que tiene una función de densidad de probabilidad , viene dado por el producto interno de y :
![{\ Displaystyle \ operatorname {E} [XY]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/612af0bbf256874e0b0551305574be507f9ff805)
![{\ Displaystyle \ operatorname {E} [X] \ cdot \ operatorname {E} [Y]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c52e5f76c5aad37aeeaf32d355681263e92aad24)
![{\ Displaystyle \ operatorname {E} [XY] = \ operatorname {E} [X] \ operatorname {E} [Y]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5cfc97e307911d3230962dd68be6a5c3dcaed71a)
![{\ Displaystyle \ operatorname {E} [XY] \ neq \ operatorname {E} [X] \ operatorname {E} [Y]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/088991fa5ad13b9421b1b14ed2b582fde070e4c1)



- [5]
- Esta fórmula también es válida en caso multidimensional, cuando es una función de varias variables aleatorias, y es su densidad articular . [5] [15]
![{\ Displaystyle \ operatorname {E} [g (X)] = \ int _ {\ mathbb {R}} g (x) f (x) \, dx.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a417b7efdd5329bcd40b2efd4b8ed5bd3b031e52)
- No degeneración: si, luego (como).
- Para una variable aleatoria con expectativa bien definida: .
- Las siguientes declaraciones con respecto a una variable aleatoria son equivalentes:
- existe y es finito.
- Ambas cosas y son finitos.
- es finito.
![{\ Displaystyle \ operatorname {E} [| X |] = 0}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ab8a77f734e7d3405900d794b5a323e2a6c58974)

![{\ Displaystyle | \ operatorname {E} [X] | \ leq \ operatorname {E} | X |}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d950496113ee61bc1f496eecbadcf6bcc85e8d62)
![{\ Displaystyle \ operatorname {E} [X ^ {+}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/21874fb6790ea26596fc561d88b159841c285fd3)
![{\ Displaystyle \ operatorname {E} [X ^ {-}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b27d36ddc1f0ffeb56f0f0e0dbc1aaa8ece17214)
![{\ Displaystyle \ operatorname {E} [| X |]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a3590a8ce161c1bf1b1bc8ef9fe99407406f2400)
- Por las razones anteriores, las expresiones " es integrable "y" el valor esperado de es finito "se utilizan indistintamente a lo largo de este artículo.
- Si luego (como) . Del mismo modo, si luego (como) .
- Si y luego
- Si (como) , entonces. En otras palabras, si X e Y son variables aleatorias que toman valores diferentes con probabilidad cero, entonces la expectativa de X será igual a la expectativa de Y.
- Si (como) para alguna constante, luego . En particular, para una variable aleatoria con expectativas bien definidas, . Una expectativa bien definida implica que hay un número, o más bien, una constante que define el valor esperado. Por lo tanto, se deduce que la expectativa de esta constante es solo el valor esperado original.
- Para una variable aleatoria de valor entero no negativo
![{\ Displaystyle \ operatorname {E} [X] <+ \ infty}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e04b1762cff984a0f687d746b5dc182a56244dfe)

![{\ Displaystyle \ operatorname {E} [X]> - \ infty}](https://wikimedia.org/api/rest_v1/media/math/render/svg/92deed236efc7deaf9c34e1a3c7c346cce28279b)





![{\ Displaystyle \ operatorname {E} [X] = \ operatorname {E} [Y]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/206f1357b15162a6f9b14f8057fe8b75a6dc82e1)
![{\ Displaystyle c \ in [- \ infty, + \ infty]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/efc16e7f0da8125427c46522d4e0fa5449dc7131)
![{\ Displaystyle \ operatorname {E} [X] = c}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8c081385ba053a066911729481c89ad435cc8c6a)
![{\ Displaystyle \ operatorname {E} [\ operatorname {E} [X]] = \ operatorname {E} [X]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7ff311903fa69e69841abfef5c018d9c43145dac)

![{\ Displaystyle \ operatorname {E} [X] = \ sum _ {n = 0} ^ {\ infty} \ operatorname {P} (X> n).}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4386ec8a6164af8d3041d07ae990592d84657dd2)
Prueba. If then On the other hand,
so the series on the right diverges to and the equality holds.
If then
Define the infinite upper-triangular matrix
The double series is the sum of 's elements if summation is done row by row. Since every summand is non-negative, the series either converges absolutely or diverges to In both cases, changing summation order does not affect the sum. Changing summation order, from row-by-row to column-by-column, gives us

![{\displaystyle \operatorname {E} [X]=+\infty .}](https://wikimedia.org/api/rest_v1/media/math/render/svg/938e66e3d486fdc141bb59d17bd29bf18b6408ad)








![{\displaystyle {\begin{aligned}\sum _{n=0}^{\infty }\sum _{j=n+1}^{\infty }\operatorname {P} (X=j)&=\sum _{j=1}^{\infty }\sum _{n=0}^{j-1}\operatorname {P} (X=j)\\&=\sum _{j=1}^{\infty }j\operatorname {P} (X=j)\\&=\sum _{j=0}^{\infty }j\operatorname {P} (X=j)\\&=\operatorname {E} [X].\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a30f0ae60992ffd04733080ac8363616732de4f9)
Usos y aplicaciones
La expectativa de una variable aleatoria juega un papel importante en una variedad de contextos. Por ejemplo, en la teoría de la decisión , a menudo se supone que un agente que hace una elección óptima en el contexto de información incompleta maximiza el valor esperado de su función de utilidad . Para un ejemplo diferente, en estadística , donde se buscan estimaciones de parámetros desconocidos con base en los datos disponibles, la estimación en sí es una variable aleatoria. En tales situaciones, un criterio deseable para un estimador "bueno" es que sea insesgado ; es decir, el valor esperado de la estimación es igual al valor real del parámetro subyacente.
Es posible construir un valor esperado igual a la probabilidad de un evento, tomando la expectativa de una función indicadora que es uno si el evento ha ocurrido y cero en caso contrario. Esta relación se puede utilizar para traducir las propiedades de los valores esperados en propiedades de probabilidades, por ejemplo, utilizando la ley de los grandes números para justificar la estimación de probabilidades por frecuencias .
Los valores esperados de las potencias de X se denominan momentos de X ; los momentos alrededor de la media de X son valores esperados de potencias de X - E [ X ]. Los momentos de algunas variables aleatorias se pueden utilizar para especificar sus distribuciones, a través de sus funciones generadoras de momentos .
Para estimar empíricamente el valor esperado de una variable aleatoria, se miden repetidamente las observaciones de la variable y se calcula la media aritmética de los resultados. Si existe el valor esperado, este procedimiento estima el verdadero valor esperado de manera insesgada y tiene la propiedad de minimizar la suma de los cuadrados de los residuos (la suma de las diferencias al cuadrado entre las observaciones y la estimación ). La ley de los números grandes demuestra (en condiciones bastante suaves) que, a medida que aumenta el tamaño de la muestra , la varianza de esta estimación se reduce.
Esta propiedad a menudo se explota en una amplia variedad de aplicaciones, incluidos problemas generales de estimación estadística y aprendizaje automático , para estimar cantidades (probabilísticas) de interés a través de métodos de Monte Carlo , ya que la mayoría de las cantidades de interés se pueden escribir en términos de expectativa, p., donde es la función indicadora del conjunto .
![{\ Displaystyle \ operatorname {P} ({X \ in {\ mathcal {A}}}) = \ operatorname {E} [{\ mathbf {1}} _ {\ mathcal {A}}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bc2d627e0e24ccb93ccedb966935f49319f4fd25)


En la mecánica clásica , el centro de masa es un concepto análogo a la expectativa. Por ejemplo, suponga que X es una variable aleatoria discreta con valores x i y sus correspondientes probabilidades p i . Ahora considere una varilla ingrávida sobre la que se colocan pesos, en las ubicaciones x i a lo largo de la varilla y que tiene masas p i (cuya suma es uno). El punto en el que la varilla se equilibra es E [ X ].
Los valores esperados también se pueden usar para calcular la varianza , por medio de la fórmula computacional para la varianza
![\ operatorname {Var} (X) = \ operatorname {E} [X ^ {2}] - (\ operatorname {E} [X]) ^ {2}.](https://wikimedia.org/api/rest_v1/media/math/render/svg/3704ee667091917e2e34f5b6e28e8d49df4b9650)
Una aplicación muy importante del valor esperado se encuentra en el campo de la mecánica cuántica . El valor esperado de un operador de mecánica cuánticaoperando en un vector de estado cuántico está escrito como . La incertidumbre en se puede calcular usando la fórmula .




Intercambiando límites y expectativas
En general, no es el caso que A pesar de puntual. Por tanto, no se pueden intercambiar límites y expectativas sin condiciones adicionales sobre las variables aleatorias. Para ver esto, deja ser una variable aleatoria distribuida uniformemente en . Para definir una secuencia de variables aleatorias
![{\ Displaystyle \ operatorname {E} [X_ {n}] \ to \ operatorname {E} [X]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2ac6f8237847b46129e5a1206c32caaf6535e2e9)


![[0,1]](https://wikimedia.org/api/rest_v1/media/math/render/svg/738f7d23bb2d9642bab520020873cccbef49768d)

![{\ Displaystyle X_ {n} = n \ cdot \ mathbf {1} \ left \ {U \ in \ left [0, {\ tfrac {1} {n}} \ right] \ right \},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/899224f356c72db5209c007f275d566baf77db5b)
con siendo la función indicadora del evento . Entonces, se sigue que(como). Pero, para cada . Por eso,


![{\ Displaystyle \ operatorname {E} [X_ {n}] = n \ cdot \ operatorname {P} \ left (U \ in \ left [0, {\ tfrac {1} {n}} \ right] \ right) = n \ cdot {\ tfrac {1} {n}} = 1}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6d8f4a245decdf6546dae0ca3b3cb7c7a81236d8)
![{\ Displaystyle \ lim _ {n \ to \ infty} \ operatorname {E} [X_ {n}] = 1 \ neq 0 = \ operatorname {E} \ left [\ lim _ {n \ to \ infty} X_ { n} \ derecha].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/17501d2c79213ad8b6b10ff2aa6b90cb3d4b5b7a)
De manera análoga, para la secuencia general de variables aleatorias , el operador de valor esperado no es -aditivo, es decir


![{\ Displaystyle \ operatorname {E} \ left [\ sum _ {n = 0} ^ {\ infty} Y_ {n} \ right] \ neq \ sum _ {n = 0} ^ {\ infty} \ operatorname {E } [Y_ {n}].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b866cf6a1cae9adf1d0fee60b0c0fe0633c6b9f1)
Un ejemplo se obtiene fácilmente configurando y por , donde es como en el ejemplo anterior.




Varios resultados de convergencia especifican condiciones exactas que permiten intercambiar límites y expectativas, como se especifica a continuación.
- Teorema de la convergencia monótona : Sea ser una secuencia de variables aleatorias, con (como) para cada . Además, dejapuntual. Entonces, el teorema de la convergencia monótona establece que



![{\ Displaystyle \ lim _ {n} \ operatorname {E} [X_ {n}] = \ operatorname {E} [X].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2b73765da42e85ed02b14edbdb043d4439a7d811)
- Usando el teorema de la convergencia monótona, se puede demostrar que la expectativa de hecho satisface la aditividad contable para las variables aleatorias no negativas. En particular, dejemosSer variables aleatorias no negativas. Se deduce del teorema de la convergencia monótona que

![{\ Displaystyle \ operatorname {E} \ left [\ sum _ {i = 0} ^ {\ infty} X_ {i} \ right] = \ sum _ {i = 0} ^ {\ infty} \ operatorname {E} [X_ {i}].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/aaf71dd77b7a0d0e91daeb404051d791320a19f2)
- Lema de Fatou : Letser una secuencia de variables aleatorias no negativas. El lema de Fatou dice que

![{\ Displaystyle \ operatorname {E} [\ liminf _ {n} X_ {n}] \ leq \ liminf _ {n} \ operatorname {E} [X_ {n}].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/057772ee68f6360861362f952828d9777135c25f)
- Corolario. Dejar con para todos . Si (como entonces
- La prueba es observando que (as) y aplicando el lema de Fatou.

![{\ Displaystyle \ operatorname {E} [X_ {n}] \ leq C}](https://wikimedia.org/api/rest_v1/media/math/render/svg/339f966e30b892a25b0670b8fc07c651a69f87ea)
![{\ Displaystyle \ operatorname {E} [X] \ leq C.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/41f7fe3f4be094774d092c875c87774a60101495)

- Teorema de convergencia dominado : Seaser una secuencia de variables aleatorias. Si puntiagudo (como), (como y . Entonces, de acuerdo con el teorema de convergencia dominado,
- ;
- Integrabilidad uniforme : en algunos casos, la igualdad se mantiene cuando la secuencia es uniformemente integrable .

![{\ Displaystyle \ operatorname {E} [Y] <\ infty}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1d673ec21dbeafe0aa85b387902be8f1e99c71ab)
![{\ Displaystyle \ operatorname {E} | X | \ leq \ operatorname {E} [Y] <\ infty}](https://wikimedia.org/api/rest_v1/media/math/render/svg/76bf5ca01b19d23933c539e345beae216814a896)
![{\ Displaystyle \ lim _ {n} \ operatorname {E} [X_ {n}] = \ operatorname {E} [X]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f107d786930dfedd1b297798933642ded4fadc31)

![{\ Displaystyle \ Displaystyle \ lim _ {n} \ operatorname {E} [X_ {n}] = \ operatorname {E} [\ lim _ {n} X_ {n}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/49b910be9482f360448e16c89ac52046dab69f9d)

Desigualdades
Hay una serie de desigualdades que involucran los valores esperados de funciones de variables aleatorias. La siguiente lista incluye algunos de los más básicos.
- Desigualdad de Markov : para una variable aleatoria no negativa y , La desigualdad de Markov establece que

![{\ Displaystyle \ operatorname {P} (X \ geq a) \ leq {\ frac {\ operatorname {E} [X]} {a}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d33c3c6fa0ecb7b99a4245dc1f55668bc50fd8cc)
- Desigualdad de Bienaymé-Chebyshev : Sea ser una variable aleatoria arbitraria con un valor esperado finito y varianza finita . La desigualdad de Bienaymé-Chebyshev establece que, para cualquier número real,
![{\ Displaystyle \ operatorname {Var} [X] \ neq 0}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8daf591feb95c7381b749d79ad0a8efb40205e53)

![{\ Displaystyle \ operatorname {P} {\ Bigl (} {\ Bigl |} X- \ operatorname {E} [X] {\ Bigr |} \ geq k {\ sqrt {\ operatorname {Var} [X]}} {\ Bigr)} \ leq {\ frac {1} {k ^ {2}}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1eae646393be5630426222c88d9594be5f140d5a)
- Desigualdad de Jensen : Seaser una función convexa de Borel y una variable aleatoria tal que . Luego


- El lado derecho está bien definido incluso si asume valores no finitos. De hecho, como se señaló anteriormente, la finitud de implica que es finito como; por lo tanto Se define como.



- Desigualdad de Lyapunov: [16] Sea. La desigualdad de Lyapunov establece que

- Prueba. Aplicando la desigualdad de Jensen a y , obtener . Tomando el la raíz de cada lado completa la prueba.





- Desigualdad de Cauchy-Bunyakovsky-Schwarz : La desigualdad de Cauchy-Bunyakovsky-Schwarz establece que
![{\ displaystyle (\ operatorname {E} [XY]) ^ {2} \ leq \ operatorname {E} [X ^ {2}] \ cdot \ operatorname {E} [Y ^ {2}].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e270eda0d23ede2b9693a7d0b0d29d014b52bdc0)
- Desigualdad de Hölder : Sea y satisfacer , , y . La desigualdad de Hölder establece que






- Desigualdad de Minkowski : Sea ser un número real positivo satisfactorio . Dejemos, además, y . Entonces, de acuerdo con la desigualdad de Minkowski, y




Valores esperados de distribuciones comunes
| Distribución | Notación | Media E (X) |
|---|---|---|
| Bernoulli | ||
| Binomio | ||
| Poisson | ||
| Geométrico | ||
| Uniforme | ||
| Exponencial | ||
| Normal | ||
| Estándar Normal | ||
| Pareto | Si | |
| Cauchy | indefinido |


















Relación con la función característica
La función de densidad de probabilidad de una variable aleatoria escalar está relacionado con su función característica por la fórmula de inversión:



Para el valor esperado de (donde es una función de Borel ), podemos usar esta fórmula de inversión para obtener

![{\ Displaystyle \ operatorname {E} [g (X)] = {\ frac {1} {2 \ pi}} \ int _ {\ mathbb {R}} g (x) \ left [\ int _ {\ mathbb {R}} e ^ {- itx} \ varphi _ {X} (t) \, \ mathrm {d} t \ right] \, \ mathrm {d} x.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4b89c3aa4e47cfc224b610f3bd5bb22914e1dc82)
Si es finito, cambiando el orden de integración, obtenemos, de acuerdo con el teorema de Fubini-Tonelli ,
![{\ Displaystyle \ operatorname {E} [g (X)]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/eb4b4bbeb1430cfba120570df9f18fb09480a7f3)
![{\ Displaystyle \ operatorname {E} [g (X)] = {\ frac {1} {2 \ pi}} \ int _ {\ mathbb {R}} G (t) \ varphi _ {X} (t) \, \ mathrm {d} t,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3f4c4680aaad76aec9e9ae3a722ba1140beafaff)
donde

es la transformada de Fourier de La expresión para también se sigue directamente del teorema de Plancherel .

Ver también
- Centro de masa
- Tendencia central
- La desigualdad de Chebyshev (una desigualdad en la ubicación y los parámetros de escala)
- Expectativa condicional
- Expectativa (el término general)
- Valor esperado (mecánica cuántica)
- Ley de expectativa total de -el valor esperado del valor esperado condicional de X dado Y es el mismo que el valor esperado de X .
- Momento (matemáticas)
- Expectativa no lineal (una generalización del valor esperado)
- Ecuación de Wald: una ecuación para calcular el valor esperado de un número aleatorio de variables aleatorias
Referencias
- ^ "Lista de símbolos de probabilidad y estadística" . Bóveda de matemáticas . 2020-04-26 . Consultado el 11 de septiembre de 2020 .
- ^ "Expectativa | Media | Promedio" . www.probabilitycourse.com . Consultado el 11 de septiembre de 2020 .
- ^ Hansen, Bruce. "PROBABILIDAD Y ESTADÍSTICAS PARA ECONOMISTAS" (PDF) . Consultado el 20 de julio de 2021 .
- ^ Wasserman, Larry. Toda la estadística: un curso conciso de inferencia estadística . Springer textos en estadística. pag. 47. ISBN 9781441923226.
- ^ a b c d Weisstein, Eric W. "Valor esperado" . mathworld.wolfram.com . Consultado el 11 de septiembre de 2020 .
- ^ a b "Valor esperado | Wiki brillante de matemáticas y ciencia" . shiny.org . Consultado el 21 de agosto de 2020 .
- ^ Historia de la probabilidad y la estadística y sus aplicaciones antes de 1750 . Serie de Wiley en Probabilidad y Estadística. 1990. doi : 10.1002 / 0471725161 . ISBN 9780471725169.
- ^ Mineral, Oystein (1960). "Ore, Pascal y la invención de la teoría de la probabilidad". The American Mathematical Monthly . 67 (5): 409–419. doi : 10.2307 / 2309286 . JSTOR 2309286 .
- ^ George Mackey (julio de 1980). "EL ANÁLISIS ARMÓNICO COMO EXPLOTACIÓN DE LA SIMETRÍA - UNA REVISIÓN HISTÓRICA". Boletín de la American Mathematical Society . Series nuevas. 3 (1): 549.
- ^ Huygens, cristiano. "El valor de las oportunidades en los juegos de la fortuna. Traducción al inglés" (PDF) .
- ^ Laplace, Pierre Simon, marqués de, 1749-1827. (1952) [1951]. Un ensayo filosófico sobre probabilidades . Publicaciones de Dover. OCLC 475539 . CS1 maint: multiple names: authors list (link)
- ^ Whitworth, WA (1901) Elección y oportunidad con mil ejercicios . Quinta edición. Deighton Bell, Cambridge. [Reimpreso por Hafner Publishing Co., Nueva York, 1959.]
- ^ "Los primeros usos de los símbolos en probabilidad y estadística" .
- ^ Richard W Hamming (1991). "Ejemplo 8.7-1 La distribución de Cauchy". El arte de la probabilidad para científicos e ingenieros . Addison-Wesley. pag. 290 y sigs . ISBN 0-201-40686-1.
El muestreo de la distribución de Cauchy y el promedio no lo lleva a ninguna parte: ¡una muestra tiene la misma distribución que el promedio de 1000 muestras!
- ^ Papoulis, A. (1984), probabilidad, variables aleatorias y procesos estocásticos , Nueva York: McGraw-Hill, págs. 139-152
- ^ Agahi, Hamzeh; Mohammadpour, Adel; Mesiar, Radko (noviembre de 2015). "Generalizaciones de algunas desigualdades de probabilidad y convergencia $ L ^ {p} $ de variables aleatorias para cualquier medida monótona" . Revista Brasileña de Probabilidad y Estadística . 29 (4): 878–896. doi : 10.1214 / 14-BJPS251 . ISSN 0103-0752 .
Literatura
- Edwards, AWF (2002). Triángulo aritmético de Pascal: la historia de una idea matemática (2ª ed.). Prensa JHU. ISBN 0-8018-6946-3.
- Huygens, Christiaan (1657). De ratiociniis in ludo aleæ (traducción al inglés, publicada en 1714) .
| vtmiTeoría de distribuciones de probabilidad | ||
|---|---|---|
|  | |
| ||
| ||